|
HDF5 Last Updated on 2026-06-27
The HDF5 Field Guide
|
|
HDF5 Last Updated on 2026-06-27
The HDF5 Field Guide
|
Navigate back: Main / HDF5 User Guide
Dimension scales are stored as datasets, with additional metadata indicating that they are to be treated as dimension scales. Each dimension scale has an optional name. There is no requirement as to where dimension scales should be stored in the file. Dimension Scale names are not required to be unique within a file. (The name of a dimension scale does not have to be the same as the HDF5 path name for the dataset representing the scale.)
Datasets are linked to dimension scales. Each dimension of a Dataset may optionally have one or more associated Dimension Scales, as well as a label for the dimension. A Dimension Scale can be shared by two or more dimensions, including dimensions in the same or different dataset. Relationships between dataset dimensions and their corresponding dimension scales are not be directly maintained or enforced by the HDF5 library. For instance, a dimension scale would not be automatically deleted when all datasets that refer to it are deleted.
Functions for creating and using Dimension Scales are implemented as high level functions, see HDF5 Dimension Scales APIs (H5DS).
A frequently requested feature is for Dimension Scales to be represented as functions, rather than a stored array of precomputed values. To meet this requirement, it is recommended that the dataset model be expanded in the future to allow datasets to be represented by a generating function.
Our study of dimension scale use cases has revealed an enormous variety of ways that dimension scales can be used. We recognize the importance of having a model that will be easy to understand and use for the vast majority of applications. It is our sense that those applications will need either no scale, a single 1-D array of floats or integers, or a simple function that provides a scale and offset.
At the same time, we want to place as few restrictions as possible on other uses of dimension scales. For instance, we don’t want to require dimension scales to be 1-D arrays, or to allow only one scale per dimension.
So our goal is to provide a model that serves the needs of two communities. We want to keep the dimension scale model conceptually simple for the majority of applications, but also to place as few restrictions as possible how dimension scales are interpreted and used. With this approach, it becomes the responsibility of applications to make sure that dimension scales satisfy the constraints of the model that they are assuming, such as constraints on the size of dimension scales and valid range of indices.
Dimension Scales are implemented as an extension of these objects. In the HDF5 Abstract Data Model, a Dataset has a Dataspace, which defines a multi dimensional array of elements. Conceptually, a Dataspace has N dimension objects, which define the current and maximum size of the array in that dimension.
It is important to emphasize that the Dataspace of a Dataset has no intrinsic meaning except to define the layout in computer storage. Dimension Scales may be used to store application specific labels to the positions in the stored data array, i.e., to add application specific meaning to the dimensions of the dataspace.
A Dimension Scale is an object associated with one dimension of a Dataspace. The meaning of the association is left to applications. The values of the Dimension Scale are set by the application to reflect semantics of the data, for example, to associate coordinates of a reference system with positions on the dimension.
In general, these associations define a mapping between values of a dimension index and values of the Dimension Scale dataset. A simple case is where the Dimension Scale s is a (one dimensional) sequence of labels for the dimension ix of Dataset d. In this case, Dimension Scale is an array indexed by the same index as in the dimension of the Dataspace. For example, for the Dimension Scale s, associated with dimension ix, the ith position of ix is associated with the value s[i], so s[i] is taken as a label for ix[i].
Figure 1 shows UML to illustrate the relationship between a Dimension and a Dimension Scale object. Conceptually, each Dimension of a Dataspace may have zero or more Dimension Scales associated with it. In turn, a Dimension Scale object may be associated with zero or more Dimensions (in zero or more Dataspaces).
Figure 2 illustrates the abstract model for a Dimension Scale object. A Dimension Scale is represented as a sub-class of a Dataset: a Dimension Scale has all the properties of a Dataset, with some specializations. A Dimension Scale dataset has an attribute “CLASS” with the value “DIMENSION_SCALE”. (This is analogous to the Table, Image, and Palette objects.) The Dimension Scale dataset has other attributes, including an optional NAME and references to any associated Dataset, as discussed below.
When the Dimension Scale is associated with a dimension of a Dataset, the association is represented by attributes of the two datasets. In the Dataset, the DIMENSION_LIST is an array of object references to scales (Dimension Scale Datasets) (Figure 1), and in the Dimension Scale Dataset the REFERENCE_LIST is an array of object references to Datasets (Figure 2).
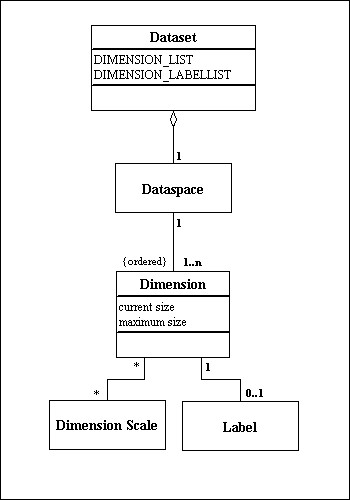
Figure 1. The relationship between a Dimension and a Dimension Scale. |
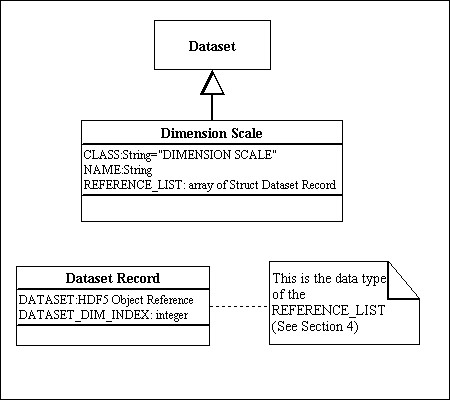
Figure 2. The definition of a Dimension Scale and its attributes. |
There seems to be good agreement that the model should accommodate scales that consist of a stored 1-D list of values, certain simple functions, and “no scale.” This specification also includes scales that are higher dimensional arrays, as well.
The four types of scales are:
A number of use cases have been proposed in which more than one scale is needed for a given dimension. This specification places no restrictions on the number of scales that can be associated with a dimension, nor on the number or identities of Dimensions that may share the same Dimension Scale.
There are use cases for storing many types of data in a scale, including, but not limited to integers, floats, and strings. Therefore, this specification places no restrictions on the datatypes of scale values: a Dimension Scale can have any HDF5 Datatype. The interpretation of dimension scale values is left to applications.
One-to-many mapping. When there are fewer values in a dimension scale than in the corresponding dimension, it is useful to have a mapping between the two. For example, mappings are used by HDF-EOS to map geolocation information to dimension, in order that, for example, every second point may have geolocation. On the other hand, the way that mappings are defined can be very idiosyncratic, and it would seem to be challenging to provide a mapping model that satisfied a large number of cases. These mappings are not included in the model specified here.
Visibility and Integrity. Since Dimension Scales are a specialization of a Dataset, it is “visible” and accessible as a regular Dataset through the HDF5 API. This means that an application program could alter the values of or delete a Dimension Scale object or required attributes without regard to any of the semantics defined in this document.
One advantage it that the implementation requires no changes to the base library, which reduces the complexity of the code and the risk of side-effects. The implementation builds on existing functions, which should improve the quality and reliability of the code. Also, this approach leaves most of the semantics of dimension scales to applications and communities, who can use the specification in any way they need.
An important disadvantage is that the core HDF5 library will not manage the semantics of Dimension Scales. In particular, applications or other software must implement:
These are briefly summarized here.
Section Programming Model and API presents an API and programming model that implements some of these features. However, applications may ignore or bypass these APIs, to write or read the attributes directly.
A Dimension Scale is stored as an HDF5 Dataset.
A Dimension Scale can be associated with a dimension of an HDF5 dataset
A dimension may have a label without a scale, and may have a scale with no label.
The implementation has two parts:
This section specifies the storage profile for Dimension Scale objects and the association between Dimensions and Dimension Scales.
This profile is compatible with an earlier netcdf prototype and the HDF4 to HDF5 Mapping. This profile is also compatible with the netCDF4 proposal. This profile may be used to augment the HDF-EOS5 profile.
See Appendix 2 for a discussion of how to store converted HDF4 objects. See Appendix 3 for a discussion of netCDF4 issues. See Appendix 4 for a discussion of HDF-EOS5.
A Dimension Scale dataset is stored as an HDF5 dataset. Table 1 summarizes the stored data, i.e., the values of the scale. There are no restrictions on the dataspace or datatype, or storage properties of the dataset.
The scale may have any HDF5 datatype, and does not have to be the same as the datatype of the Dataset(s) that use the scale. E.g., an integer dataset might have dimension scales that are string or float values.
The dataspace of the scale can be any rank and shape. A scale is not limited to one dimension, and is not restricted by the size of any dimension(s) associated with it. When a dimension is associated with a one dimensional scale, the scale may be a different size from the dimension. In this case, it is up to the application to interpret or resolve the difference. When a dimension is associated with a scale with a rank higher than 1, the interpretation of the association is up to the application.
The Dimension Scale dataset can use any storage properties (including fill values, filters, and storage layout), not limited by the properties of any datasets that refer to it. When the Dimension Scale is extendible, it must be chunked.
Table 2 defines the required and optional attributes of the Dimension Scale Dataset. The attribute REFERENCE_LIST is a list of (dataset, index) pairs. Each pair represents an association defined by ‘attach_scale’. These pairs are stored as an array of compound data. Table 3 defines this datatype.
The Dimension Scale Dataset has an attribute called SUB_CLASS. This string is intended to be used to document particular specializations of this profile, e.g., a Dimension Scale created by netCDF4.
| Field | Datatype | Dataspace | Storage Properties | Notes |
|---|---|---|---|---|
| <data> | Any | Any | Any | These are the values of the Dimension Scale. |
| Attribute Name | Datatype and Dimensions | Value | Required / Optional | Notes |
|---|---|---|---|---|
| CLASS | H5T_STRING length = 16 | “DIMENSION_SCALE” | Required | This attribute distinguishes the dataset as a Dimension scale object. This is set by H5DSset_scale |
| NAME | H5T_STRING length = <user defined> | <user defined> The name does not have to be the same as the HDF5 path name for the dataset. The name does not have to be related to any labels. Several Dimension Scales may have the same name. | Optional, (Maximum of 1) | The user defined label of the Dimension Scale. This is set by H5DSset_label |
| REFERENCE_LIST | Array of Dataset Reference Type (Compound Datatype), variable length. | [ {dataset1, ind1 }, …] [,…] ….] | Optional, required when scale is attached | See Table 3. This is set by H5DSattach_scale. |
| SUB_CLASS | H5T_STRING length = <profile defined> | “HDF4_DIMENSION”, “NC4_DIMENSION”, | Optional, defined by other profiles | This is used to indicate a specific profile was used. |
| <Other attributes> | Optional | For example, UNITS. |
| Field | Datatype | Value | Notes |
|---|---|---|---|
| DATASET | Object Reference. | Pointer to a Dataset that refers to the scale | Set by H5DSattach_scale. Removed by H5DSdetach_scale. |
| INDEX | H5T_NATIVE_INT | Index of the dimension the dataset pointed to by DATASET | Set by H5DSattach_scale. Removed by H5DSdetach_scale. |
A Dataset may have zero or more Dimension Scales associated with its dataspace. When present, these associations are represented by two attributes of the Dataset. Table 4 defines these attributes.
The DIMENSION_LIST is a two dimensional array with one row for each dimension of the Dataset, and a variable number of entries in each row, one for each associated scale. This is stored as a one dimensional array, with the HDF5 Datatype variable length array of object references.
When a dimension has more than one scale, the order of the scales in the DIMENSION_LIST attribute is not defined. A given Dimension Scale should appear in the list only once. (I.E., the DIMENSION_LIST is a “set”.)
When a scale is shared by more than one dimension (of one or more Dataset), the order of the records in REFERENCE_LIST is not defined. The Dataset and Dimension should appear in the list only once.
| Attribute Name | Datatype and Dimensions | Value | Required / Optional | Notes |
|---|---|---|---|---|
| DIMENSION_LIST | The HDF5 datatype is ARRAY of Variable Length H5T_STD_REF_OBJ with rank of the dataspace. | [[{object__ref1, object__ref2, … object__refn}, …] […] ..] | Optional, required if scales are attached | Set by H5DSattach_scale. Entries removed by H5DSdetach_scale. |
| DIMENSION_LABELLIST | The HDF5 datatype is ARRAY of H5T_STRING with rank of the dataspace. | [ <Label1>, <Label2>, …, <Label3>] | Optional, required for scales with a label | Set by H5DSset_label. |
Dimension scales are often referred to by name, so Dimension Scales may have names. Since some applications do not wish to apply names to dimension scales, Dimension Scale names be optional. In addition, some applications will have a name but no associated data values for a dimension (i.e., just a label). To support this, each dimension may have a label, which may be but need not be the same as the name of an associated Dimension Scale.
Dimension Scale Name. Associated with the Dimension Scale object. A Dimension Scale may have no name, or one name.
Dimension Label. A optional label associated with a dimension of a Dataset.
How is a name represented? Three options seem reasonable:
Dimension Scale names are stored in attributes of the Dimension Scale or the Dataset that refers to a Dimension Scale.
Should dimension scale names be unique among dimension scales within a file? We have seen a number of cases in which applications need more than one dimension scale with the same name. We have also seen applications where the opposite is true: dimension scale names are assumed to be unique within a file. This specification leaves it to applications to enforce a policy of uniqueness when they need it.
Can a dimension have a label, without having an associated scale? Some applications may wish to name dimensions without having an associated scale. Therefore, a dataset may have a label for a dimension without having an associated Dimension Scale dataset.
Can a dimension have a scale, without having an associated label? Some applications may wish to assign a dimension scale with no label. Therefore, a dataset may have one or more Dimension Scales for a dimension without having an associated label.
Anonymous Dimensions. It is possible to have a Dimension Scale dataset with no name, and associate it with a dimension of a dataset with no label. This case associates an array of data values to the dimension, but no identifier.
A dimension with a label and a name. A dimension of a dataset can be associated with a Dimension Scale that has a name, and assigned a label. In this case, the association has two “names”, the label and the dimension scale name. It is up to applications to interpret these names.
Table 5 summarizes the six possible combinations of label and name.
| No scale | Scale with no name | Scale with name | |
|---|---|---|---|
| No label | Dimension has no label or scale (default) | Dimension has an anonymous scale | Dimension has scale, the scale is called “name” |
| Label | Dimension has label | Dimension has scale with a label. | Dimension has scale with both a label and name. A shared dimension has one name, but may have several labels |
Given the design described above, datasets can share dimension scales. The following additional capabilities would seem to be useful.
These capabilities can be provided in several ways:
This specification defines attributes that maintain back pointers, which enable these kinds of cross referencing. Other software, such as NetCDF4, may well need a global table to track a set of dimensions. Such a table can be done in addition to the attributes defined here.
This section presents an example to illustrate the data structures defined above.
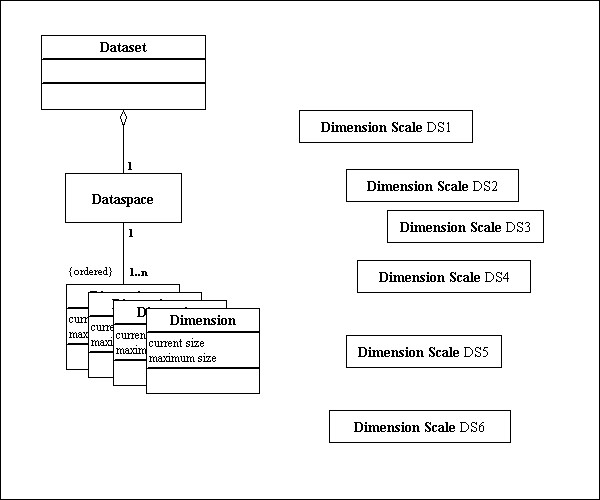
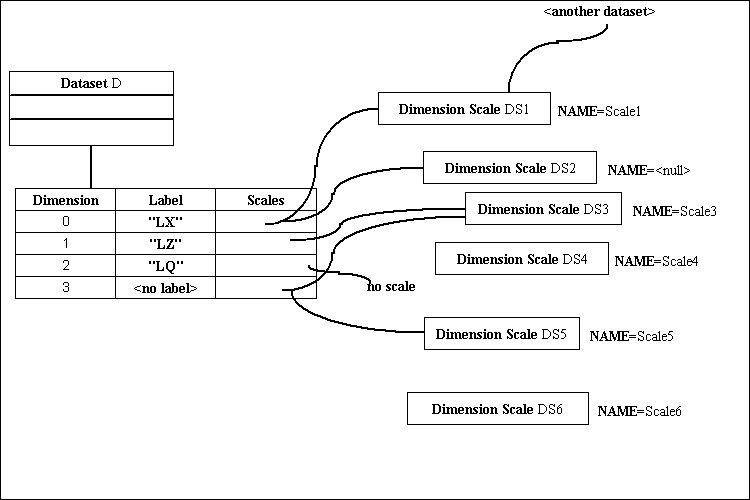
Figure 3 shows a Dataset with a four dimensional Dataspace. The file also contains six Dimension Scale datasets. The Dimension Scale datasets are HDF5 objects, with path names such as “/DS1”.
Figure 4 illustrates the use of dimension scales in this example. Each Dimension Scale Dataset has an optional NAME. For example, “/DS3” has been assigned the name “Scale3”.
The dimensions of dataset D have been assigned zero or more scales and labels. Dimension 0 has two scales, Dimension 1 has one scale, and so on. Dimension 2 has no scale associated with it.
Some of the dimensions have labels as well. Note that dimension 2 has a label but no scale, and dimension 3 has scales but no label.
Some of the Dimension Scales are shared. Dimension Scale DS1 is referenced by dimension 0 of D and by another unspecified dataset. Dimension Scale DS3 is referenced by dimension 1 and 3 of Dataset D.
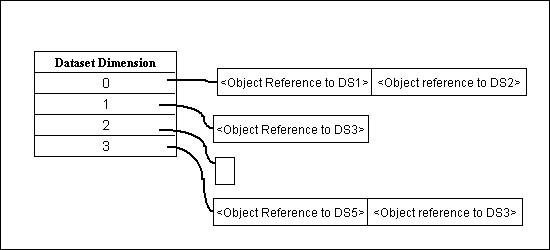
These relationships are represented in the file by attributes of the Dataset D and the Dimension Scale Datasets. Figure 5 shows the values that are stored for the DIMENSION_LIST attribute of Dataset D.
This attribute is a one-dimensional array with the HDF5 datatype variable length H5T_STD_REF_OBJ. Each row of the array is zero or more object references for Dimension Scale datasets.
Table 6 shows the DIMENSION_LABELLIST for Dataset D. This is a one dimensional array with some empty values.
Each of the Dimension Scale Datasets has a name and other attributes. The references are represented in the REFERENCE_LIST attributes. Table 7 – Table 10 show the values for these tables. Note that Dimension Scale DS4 and DS6 have no references to them in this diagram.
The tables are stored as attributes of the Dimension Scale Dataset and the Datasets that refer to scales. Essentially, the association between a dimension of a Dataset and a Dimension Scale is represented by “pointers” (i.e., HDF5 Object References) in both of the associated objects. Since there can be multiple associations, there can be multiple pointers stored at each object, representing the endpoints of the associations. These will be stored in tables, i.e., as an attribute with an array of values.
When dimension scales are attached or detached, the tables in the Dataset and the Dimension Scale must be updated. The arrays in the attributes can grow, and items can be deleted.
The associations are identified by the object reference and dimension which is stored in a back pointer and returned from an API. The detach function needs to be careful how it deletes an item from the table, because the entries at both ends of the association must be updated at the same time.
| Dataset Dimension | Label |
|---|---|
| 0 | “LX” |
| 1 | “LZ” |
| 2 | “LQ” |
| 3 | “” |
| Reference | Dataset Reference Record |
|---|---|
| 0 | {Object reference to Dataset D, 0} |
| 1 | {Object reference to other Dataset, ?} |
| Reference | Dataset Reference Record |
|---|---|
| 0 | {Object reference to Dataset D, 0} |
| Reference | Dataset Reference Record |
|---|---|
| 0 | {Object reference to Dataset D, 1} |
| 1 | {Object reference to Dataset D, 3} |
| Reference | Dataset Reference Record |
|---|---|
| 0 | {Object reference to Dataset D, 3} |
Dimension Scales are HDF5 Datasets, so they may be created and accesses through any HDF5 API for datasets [10]. The HDF5 Dimension Scale API implements the specification defined in this document. The operations include:
The API also defines operations for dimension labels:
When an extendible Dataset has Dimension Scales, it is necessary to coordinate when the dimensions change size.
The detach operation removes an association between a dimension and a scale. It does not delete the Dimension Scale Dataset.
When it is necessary to delete a Dimension Scale Dataset, it is necessary to detach it from all dataset. This section outlines the necessary steps.
When it is necessary to delete a dataset that has scales attached, it is necessary to delete all the scales before deleting the dataset. Here is a sketch of the steps.
Attach dimension scales to datasets using H5DSattach_scale and detach with H5DSdetach_scale. Set and retrieve dimension scale names with H5DSset_scale and H5DSget_scale_name. Query if a dataset is a dimension scale with H5DSis_scale and check attachments with H5DSis_attached. Iterate through scales with H5DSiterate_scales.
Previous Chapter Direct Chunk Write Function - Next Chapter HDF5 Images
Navigate back: Main / HDF5 User Guide