|
HDF5 2.0.0.258fa78
API Reference
|
|
HDF5 2.0.0.258fa78
API Reference
|
The HDF5 Virtual Dataset (VDS) feature enables users to access data in a collection of HDF5 files as a single HDF5 dataset and to use the HDF5 APIs to work with that dataset.
For example, your data may be collected into four files: 
You can map the datasets in the four files into a single VDS that can be accessed just like any other dataset: 
The mapping between a VDS and the HDF5 source datasets is persistent and transparent to an application. If a source file is missing the fill value will be displayed.
See the Virtual (VDS) Documentation for complete details regarding the VDS feature.
The VDS feature was implemented using hyperslab selection (H5Sselect_hyperslab). See the tutorial on Reading From or Writing to a Subset of a Dataset for more information on selecting hyperslabs.
To create a Virtual Dataset you simply follow the HDF5 programming model and add a few additional API calls to map the source code datasets to the VDS.
Following are the steps for creating a Virtual Dataset:
The H5Pset_virtual API sets the mapping between virtual and source datasets. This is a dataset creation property list. Using this API will change the layout of the dataset to H5D_VIRTUAL. As with specifying any dataset creation property list, an instance of the property list is created, modified, passed into the dataset creation call and then closed:
There are several other APIs introduced with Virtual Datasets, including query functions. For details see the complete list of HDF5 library APIs that support Virtual Datasets.
This feature was introduced in HDF5-1.10.
The number of source datasets is unlimited. However, there is a limit on the size of each source dataset.
Example 1 This example creates three HDF5 files, each with a one-dimensional dataset of 6 elements. The datasets in these files are the source datasets that are then used to create a 4 x 6 Virtual Dataset with a fill value of -1. The first three rows of the VDS are mapped to the data from the three source datasets as shown below: 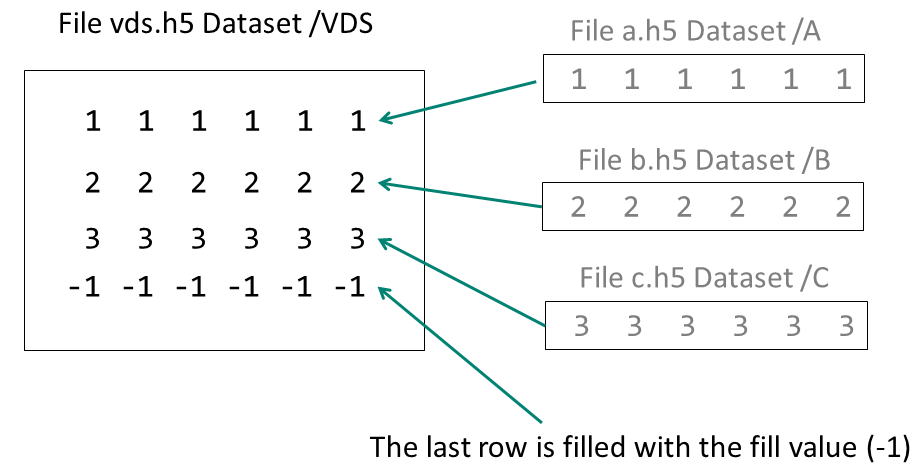
In this example the three source datasets are mapped to the VDS with this code:
The b indicates that the block count of the selection in the dimension should be used.
For details on compiling an HDF5 application: [ Compiling HDF5 Applications ]
Using h5dump with a VDS The h5dump utility can be used to view a VDS. The h5dump output for a VDS looks exactly like that for any other dataset. If h5dump cannot find a source dataset then the fill value will be displayed.
You can determine that a dataset is a VDS by looking at its properties with
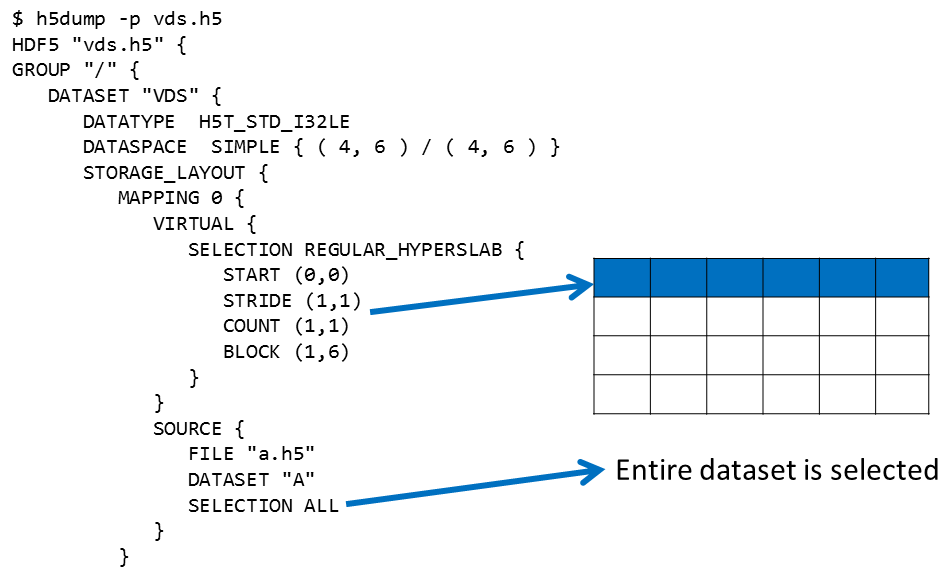
It will display each source dataset mapping, beginning with Mapping 0. Below is an excerpt of the output of
on the vds.h5 file created in Example 1.You can see that the entire source file a.h5 is mapped to the first row of the VDS dataset.
 1.9.7
1.9.7 