|
HDF5 1.14.6
API Reference
|
|
HDF5 1.14.6
API Reference
|
HDF5 datatypes describe the element type of HDF5 datasets and attributes. There's a large set of predefined datatypes, but users may find it useful to define new datatypes through a process called derivation.
The element type is automatically persisted as part of the HDF5 metadata of attributes and datasets. Additionally, datatype definitions can be persisted to HDF5 files and linked to groups as HDF5 datatype objects or so-called committed datatypes.
An HDF5 dataset is an array of data elements, arranged according to the specifications of the dataspace. In general, a data element is the smallest addressable unit of storage in the HDF5 file. (Compound datatypes are the exception to this rule.) The HDF5 datatype defines the storage format for a single data element. See the figure below.
The model for HDF5 attributes is extremely similar to datasets: an attribute has a dataspace and a data type, as shown in the figure below. The information in this chapter applies to both datasets and attributes.
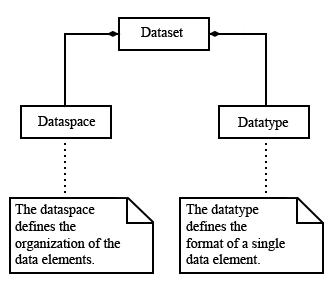
Datatypes, dataspaces, and datasets |
Abstractly, each data element within the dataset is a sequence of bits, interpreted as a single value from a set of values (for example, a number or a character). For a given datatype, there is a standard or convention for representing the values as bits, and when the bits are represented in a particular storage the bits are laid out in a specific storage scheme such as 8-bit bytes with a specific ordering and alignment of bytes within the storage array.
HDF5 datatypes implement a flexible, extensible, and portable mechanism for specifying and discovering the storage layout of the data elements, determining how to interpret the elements (for example, as floating point numbers), and for transferring data from different compatible layouts.
An HDF5 datatype describes one specific layout of bits. A dataset has a single datatype which applies to every data element. When a dataset is created, the storage datatype is defined. After the dataset or attribute is created, the datatype cannot be changed.
When data is transferred (for example, a read or write), each end point of the transfer has a datatype, which describes the correct storage for the elements. The source and destination may have different (but compatible) layouts, in which case the data elements are automatically transformed during the transfer.
HDF5 datatypes describe commonly used binary formats for numbers (integers and floating point) and characters (ASCII). A given computing architecture and programming language supports certain number and character representations. For example, a computer may support 8-, 16-, 32-, and 64-bit signed integers, stored in memory in little-endian byte order. These would presumably correspond to the C programming language types char, short, int, and long.
When reading and writing from memory, the HDF5 library must know the appropriate datatype that describes the architecture specific layout. The HDF5 library provides the platform independent NATIVE types, which are mapped to an appropriate datatype for each platform. So the type H5T_NATIVE_INT is an alias for the appropriate descriptor for each platform.
Data in memory has a datatype:
In addition to numbers and characters, an HDF5 datatype can describe more abstract classes of types including enumerations, strings, bit strings, and references (pointers to objects in the HDF5 file). HDF5 supports several classes of composite datatypes which are combinations of one or more other datatypes. In addition to the standard predefined datatypes, users can define new datatypes within the datatype classes.
The HDF5 datatype model is very general and flexible:
The HDF5 library implements an object-oriented model of datatypes. HDF5 datatypes are organized as a logical set of base types, or datatype classes. Each datatype class defines a format for representing logical values as a sequence of bits. For example the H5T_INTEGER class is a format for representing twos complement integers of various sizes.
A datatype class is defined as a set of one or more datatype properties. A datatype property is a property of the bit string. The datatype properties are defined by the logical model of the datatype class. For example, the integer class (twos complement integers) has properties such as “signed or unsigned”, “length”, and “byte-order”. The float class (IEEE floating point numbers) has these properties, plus “exponent bits”, “exponent sign”, etc.
A datatype is derived from one datatype class: a given datatype has a specific value for the datatype properties defined by the class. For example, for 32-bit signed integers, stored big-endian, the HDF5 datatype is a sub-type of integer with the properties set to signed=1, size=4(bytes), and byte-order=BE.
The HDF5 datatype API (H5T functions) provides methods to create datatypes of different datatype classes, to set the datatype properties of a new datatype, and to discover the datatype properties of an existing datatype.
The datatype for a dataset is stored in the HDF5 file as part of the metadata for the dataset. A datatype can be shared by more than one dataset in the file if the datatype is saved to the file with a name. This shareable datatype is known as a committed datatype. In the past, this kind of datatype was called a named datatype.
When transferring data (for example, a read or write), the data elements of the source and destination storage must have compatible types. As a general rule, data elements with the same datatype class are compatible while elements from different datatype classes are not compatible. When transferring data of one datatype to another compatible datatype, the HDF5 Library uses the datatype properties of the source and destination to automatically transform each data element. For example, when reading from data stored as 32-bit signed integers, big endian into 32-bit signed integers, little-endian, the HDF5 Library will automatically swap the bytes.
Thus, data transfer operations (H5Dread, H5Dwrite, H5Aread, H5Awrite) require a datatype for both the source and the destination.
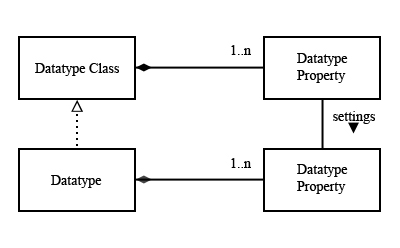
The datatype model |
The HDF5 library defines a set of predefined datatypes, corresponding to commonly used storage formats, such as twos complement integers, IEEE Floating point numbers, etc., 4- and 8-byte sizes, big-endian and little-endian byte orders. In addition, a user can derive types with custom values for the properties. For example, a user program may create a datatype to describe a 6-bit integer, or a 600-bit floating point number.
In addition to atomic datatypes, the HDF5 library supports composite datatypes. A composite datatype is an aggregation of one or more datatypes. Each class of composite datatypes has properties that describe the organization of the composite datatype. See the figure below. Composite datatypes include:
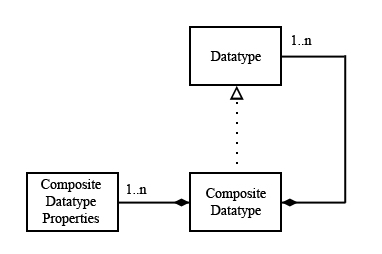
Composite datatypes |
The figure below shows the HDF5 datatype classes. Each class is defined to have a set of properties which describe the layout of the data element and the interpretation of the bits. The table below lists the properties for the datatype classes.
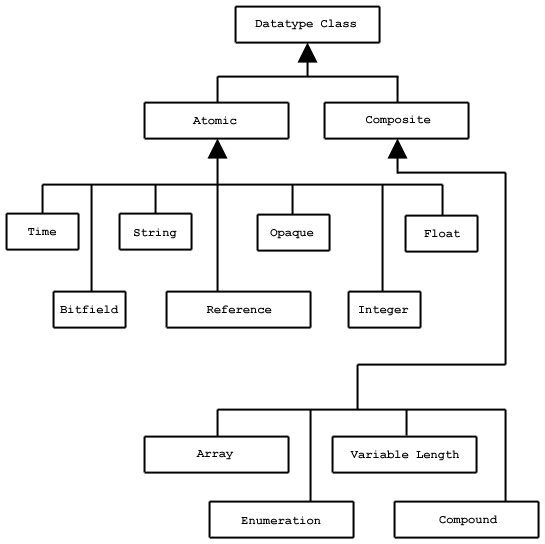
Datatype classes |
| Class | Description | Properties | Notes |
|---|---|---|---|
| Integer | Twos complement integers | Size (bytes), precision (bits), offset (bits), pad, byte order, signed/unsigned | |
| Float | Floating Point numbers | Size (bytes), precision (bits), offset (bits), pad, byte order, sign position, exponent position, exponent size (bits), exponent sign, exponent bias, mantissa position, mantissa (size) bits, mantissa sign, mantissa normalization, internal padding | See IEEE 754 for a definition of these properties. These properties describe non-IEEE 754 floating point formats as well. |
| Character | Array of 1-byte character encoding | Size (characters), Character set, byte order, pad/no pad, pad character | Currently, ASCII and UTF-8 are supported. |
| Bitfield | String of bits | Size (bytes), precision (bits), offset (bits), pad, byte order | A sequence of bit values packed into one or more bytes. |
| Opaque | Uninterpreted data | Size (bytes), precision (bits), offset (bits), pad, byte order, tag | A sequence of bytes, stored and retrieved as a block. The ‘tag’ is a string that can be used to label the value. |
| Enumeration | A list of discrete values, with symbolic names in the form of strings. | Number of elements, element names, element values | Enumeration is a list of pairs (name, value). The name is a string; the value is an unsigned integer. |
| Reference | Reference to object or region within the HDF5 file |
| |
| Array | Array (1-4 dimensions) of data elements | Number of dimensions, dimension sizes, base datatype | The array is accessed atomically: no selection or sub-setting. |
| Variable-length | A variable-length 1-dimensional array of data elements | Current size, base type | |
| Compound | A Datatype of a sequence of Datatypes | Number of members, member names, member types, member offset, member class, member size, byte order |
The HDF5 library predefines a modest number of commonly used datatypes. These types have standard symbolic names of the form H5T_arch_base where arch is an architecture name and base is a programming type name Table 2. New types can be derived from the predefined types by copying the predefined type H5Tcopy() and then modifying the result.
The base name of most types consists of a letter to indicate the class Table 3, a precision in bits, and an indication of the byte order Table 4.
Table 5 shows examples of predefined datatypes. The full list can be found in the Predefined Datatypes section of the HDF5 Reference Manual.
| Architecture Name | Description |
|---|---|
| IEEE | IEEE-754 standard floating point types in various byte orders. |
| STD | This is an architecture that contains semi-standard datatypes like signed two's complement integers, unsigned integers, and bitfields in various byte orders. |
| C <br > FORTRAN | Types which are specific to the C or Fortran programming languages are defined in these architectures. For instance, H5T_C_S1 defines a base string type with null termination which can be used to derive string types of other lengths. |
| NATIVE | This architecture contains C-like datatypes for the machine for which the library was compiled. In order to be portable, applications should almost always use this architecture to describe things in memory. |
| CRAY | Cray architectures. These are word-addressable, big-endian systems with non-IEEE floating point. |
| INTEL | All Intel and compatible CPUs. These are little-endian systems with IEEE floating-point. |
| MIPS | All MIPS CPUs commonly used in SGI systems. These are big-endian systems with IEEE floating-point. |
| ALPHA | All DEC Alpha CPUs, little-endian systems with IEEE floating-point. |
| Base | Description |
|---|---|
| B | Bitfield |
| F | Floating point |
| I | Signed integer |
| R | References |
| S | Character string |
| U | Unsigned integer |
| Order | Description |
|---|---|
| BE | Big-endian |
| LE | Little-endian |
| Example | Description |
|---|---|
| H5T_IEEE_F64LE | Eight-byte, little-endian, IEEE floating-point |
| H5T_IEEE_F32BE | Four-byte, big-endian, IEEE floating point |
| H5T_STD_I32LE | Four-byte, little-endian, signed two's complement integer |
| H5T_STD_U16BE | Two-byte, big-endian, unsigned integer |
| H5T_C_S1 | One-byte,null-terminated string of eight-bit characters |
| H5T_INTEL_B64 | Eight-byte bit field on an Intel CPU |
| H5T_STD_REF | Reference to an object in a file |
The HDF5 library predefines a set of NATIVE datatypes which are similar to C type names. The native types are set to be an alias for the appropriate HDF5 datatype for each platform. For example, H5T_NATIVE_INT corresponds to a C int type. On an Intel based PC, this type is the same as H5T_STD_I32LE, while on a MIPS system this would be equivalent to H5T_STD_I32BE. Table 6 shows examples of NATIVE types and corresponding C types for a common 32-bit workstation.
| Example | Corresponding C Type |
|---|---|
| H5T_NATIVE_CHAR | char |
| H5T_NATIVE_SCHAR | signed char |
| H5T_NATIVE_UCHAR | unsigned char |
| H5T_NATIVE_SHORT | short |
| H5T_NATIVE_USHORT | unsigned short |
| H5T_NATIVE_INT | int |
| H5T_NATIVE_UINT | unsigned |
| H5T_NATIVE_LONG | long |
| H5T_NATIVE_ULONG | unsigned long |
| H5T_NATIVE_LLONG | long long |
| H5T_NATIVE_ULLONG | unsigned long long |
| H5T_NATIVE_FLOAT16 | _Float16 |
| H5T_NATIVE_FLOAT | float |
| H5T_NATIVE_DOUBLE | double |
| H5T_NATIVE_LDOUBLE | long double |
| H5T_NATIVE_HSIZE | hsize_t |
| H5T_NATIVE_HSSIZE | hssize_t |
| H5T_NATIVE_HERR | herr_t |
| H5T_NATIVE_HBOOL | bool |
| H5T_NATIVE_B8 | 8-bit unsigned integer or 8-bit buffer in memory |
| H5T_NATIVE_B16 | 16-bit unsigned integer or 16-bit buffer in memory |
| H5T_NATIVE_B32 | 32-bit unsigned integer or 32-bit buffer in memory |
| H5T_NATIVE_B64 | 64-bit unsigned integer or 64-bit buffer in memory |
The HDF5 library manages datatypes as objects. The HDF5 datatype API manipulates the datatype objects through C function calls. New datatypes can be created from scratch or copied from existing datatypes. When a datatype is no longer needed its resources should be released by calling H5Tclose().
The datatype object is used in several roles in the HDF5 data model and library. Essentially, a datatype is used whenever the form at of data elements is needed. There are four major uses of datatypes in the HDF5 library: at dataset creation, during data transfers, when discovering the contents of a file, and for specifying user-defined datatypes. See the table below.
| Use | Description |
|---|---|
| Dataset creation | The datatype of the data elements must be declared when the dataset is created. |
| Dataset transfer | The datatype (format) of the data elements must be defined for both the source and destination. |
| Discovery | The datatype of a dataset can be interrogated to retrieve a complete description of the storage layout. |
| Creating user-defined datatypes | Users can define their own datatypes by creating datatype objects and setting their properties. |
All the data elements of a dataset have the same datatype. When a dataset is created, the datatype for the data elements must be specified. The datatype of a dataset can never be changed. The example below shows the use of a datatype to create a dataset called “/dset”. In this example, the dataset will be stored as 32-bit signed integers in big-endian order.
Using a datatype to create a dataset
Probably the most common use of datatypes is to write or read data from a dataset or attribute. In these operations, each data element is transferred from the source to the destination (possibly rearranging the order of the elements). Since the source and destination do not need to be identical (in other words, one is disk and the other is memory), the transfer requires both the format of the source element and the destination element. Therefore, data transfers use two datatype objects, for the source and destination.
When data is written, the source is memory and the destination is disk (file). The memory datatype describes the format of the data element in the machine memory, and the file datatype describes the desired format of the data element on disk. Similarly, when reading, the source datatype describes the format of the data element on disk, and the destination datatype describes the format in memory.
In the most common cases, the file datatype is the datatype specified when the dataset was created, and the memory datatype should be the appropriate NATIVE type. The examples below show samples of writing data to and reading data from a dataset. The data in memory is declared C type ‘int’, and the datatype H5T_NATIVE_INT corresponds to this type. The datatype of the dataset should be of datatype class H5T_INTEGER.
Writing to a dataset
Reading from a dataset
The HDF5 Library enables a program to determine the datatype class and properties for any datatype. In order to discover the storage format of data in a dataset, the datatype is obtained, and the properties are determined by queries to the datatype object. The example below shows code that analyzes the datatype for an integer and prints out a description of its storage properties (byte order, signed, size).
Discovering datatype properties
Most programs will primarily use the predefined datatypes described above, possibly in composite data types such as compound or array datatypes. However, the HDF5 datatype model is extremely general; a user program can define a great variety of atomic datatypes (storage layouts). In particular, the datatype properties can define signed and unsigned integers of any size and byte order, and floating point numbers with different formats, size, and byte order. The HDF5 datatype API provides methods to set these properties.
User-defined types can be used to define the layout of data in memory; examples might match some platform specific number format or application defined bit-field. The user-defined type can also describe data in the file such as an application-defined format. The user-defined types can be translated to and from standard types of the same class, as described above.
see Datatypes (H5T) reference manual provides a reference list of datatype functions, the H5T APIs.
The HDF5 Library implements an object-oriented model of datatypes. HDF5 datatypes are organized as a logical set of base types, or datatype classes. The HDF5 Library manages datatypes as objects. The HDF5 datatype API manipulates the datatype objects through C function calls. The figure below shows the abstract view of the datatype object. The table below shows the methods (C functions) that operate on datatype objects. New datatypes can be created from scratch or copied from existing datatypes.
The datatype object |
| API Function | Description |
|---|---|
| hid_t H5Tcreate (H5T_class_t class, size_t size) | Create a new datatype object of the specified datatype class with the specified size. This function is only used with the following datatype classes:
|
| hid_t H5Tarray_create2 (hid_t base_id, unsigned ndims, const hsize_t dim[]); | Create a new array datatype object. base_id is the datatype of every element of the array, i.e., of the number at each position in the array. ndims is the number of dimensions and the size of each dimension is specified in the array dim. |
| hid_t H5Tvlen_create (hid_t base_id); | Create a new one-dimensional variable-length array datatype object. base_id is the datatype of every element of the array. |
| hid_t H5Tenum_create (hid_t base_id); | Create a new enumeration datatype object. base_id is the datatype of every element of the enumeration datatype. |
| hid_t H5Tcopy (hid_t type) | Obtain a modifiable transient datatype which is a copy of type. If type is a dataset identifier then the type returned is a modifiable transient copy of the datatype of the specified dataset. |
| hid_t H5Topen (hid_t location, const char *name, H5P_DEFAULT) | Open a committed datatype. The committed datatype returned by this function is read-only. |
| htri_t H5Tequal (hid_t type1, hid_t type2) | Determines if two types are equal. |
| herr_t H5Tclose (hid_t type) | Releases resources associated with a datatype obtained from H5Tcopy, H5Topen, or H5Tcreate / H5Tarray_create2 / etc. It is illegal to close an immutable transient datatype (for example, predefined types). |
| herr_t H5Tcommit (hid_t location, const char *name, hid_t type, H5P_DEFAULT, H5P_DEFAULT, H5P_DEFAULT) | Commit a transient datatype (not immutable) to a file to become a committed datatype. Committed datatypes can be shared. |
| htri_t H5Tcommitted (hid_t type) | Test whether the datatype is transient or committed (named). |
| herr_t H5Tlock (hid_t type) | Make a transient datatype immutable (read-only and not closable). Predefined types are locked. |
In order to use a datatype, the object must be created (H5Tcreate / H5Tarray_create2 / etc.), or a reference obtained by cloning from an existing type (H5Tcopy), or opened (H5Topen). In addition, a reference to the datatype of a dataset or attribute can be obtained with H5Dget_type or H5Aget_type. For composite datatypes a reference to the datatype for members or base types can be obtained (H5Tget_member_type, H5Tget_super). When the datatype object is no longer needed, the reference is discarded with H5Tclose.
Two datatype objects can be tested to see if they are the same with H5Tequal. This function returns true if the two datatype references refer to the same datatype object. However, if two datatype objects define equivalent datatypes (the same datatype class and datatype properties), they will not be considered ‘equal’.
A datatype can be written to the file as a first class object (H5Tcommit). This is a committed datatype and can be used in the same way as any other datatype.
Any HDF5 datatype object can be queried to discover all of its datatype properties. For each datatype class, there are a set of API functions to retrieve the datatype properties for this class.
Table 9 lists the functions to discover the properties of atomic datatypes. Table 10 lists the queries relevant to specific numeric types. Table 11 gives the properties for atomic string datatype, and Table 12 gives the property of the opaque datatype.
| API Function | Description |
|---|---|
| H5T_class_t H5Tget_class (hid_t type) | The datatype class: H5T_INTEGER, H5T_FLOAT, H5T_STRING, H5T_BITFIELD, H5T_OPAQUE, H5T_COMPOUND, H5T_REFERENCE, H5T_ENUM, H5T_VLEN, H5T_ARRAY |
| size_t H5Tget_size (hid_t type) | The total size of the element in bytes, including padding which may appear on either side of the actual value. |
| H5T_order_t H5Tget_order (hid_t type) | The byte order describes how the bytes of the datatype are laid out in memory. If the lowest memory address contains the least significant byte of the datum then it is said to be little-endian or H5T_ORDER_LE. If the bytes are in the opposite order then they are said to be big-endianor H5T_ORDER_BE. |
| size_t H5Tget_precision (hid_t type) | The precision property identifies the number of significant bits of a datatype and the offset property (defined below) identifies its location. Some datatypes occupy more bytes than what is needed to store the value. For instance, a short on a Cray is 32 significant bits in an eight-byte field. |
| int H5Tget_offset (hid_t type) | The offset property defines the bit location of the least significant bit of a bit field whose length is precision. |
| herr_t H5Tget_pad (hid_t type, H5T_pad_t *lsb, H5T_pad_t *msb) | Padding is the bits of a data element which are not significant as defined by the precision and offset properties. Padding in the low-numbered bits is lsb padding and padding in the high-numbered bits is msb padding. Padding bits can be set to zero (H5T_PAD_ZERO) or one (H5T_PAD_ONE). |
| API Function | Description |
|---|---|
| H5T_sign_t H5Tget_sign (hid_t type) | (INTEGER)Integer data can be signed two's complement (H5T_SGN_2) or unsigned (H5T_SGN_NONE). |
| herr_t H5Tget_fields (hid_t type, size_t *spos, size_t *epos, size_t *esize, size_t*mpos, size_t *msize) | (FLOAT)A floating-point data element has bit fields which are the exponent and mantissa as well as a mantissa sign bit. These properties define the location (bit position of least significant bit of the field) and size (in bits) of each field. The sign bit is always of length one and none of the fields are allowed to overlap. |
| size_t H5Tget_ebias (hid_t type) | (FLOAT)A floating-point data element has bit fields which are the exponent and mantissa as well as a mantissa sign bit. These properties define the location (bit position of least significant bit of the field) and size (in bits) of each field. The sign bit is always of length one and none of the fields are allowed to overlap. |
| H5T_norm_t H5Tget_norm (hid_t type) | (FLOAT)This property describes the normalization method of the mantissa.
|
| H5T_pad_t H5Tget_inpad (hid_t type) | (FLOAT)If any internal bits (that is, bits between the sign bit, the mantissa field, and the exponent field but within the precision field) are unused, then they will be filled according to the value of this property. The padding can be: H5T_PAD_BACKGROUND, H5T_PAD_ZERO,or H5T_PAD_ONE. |
| API Function | Description |
|---|---|
| H5T_cset_t H5Tget_cset (hid_t type) | Two character sets are currently supported: ASCII (H5T_CSET_ASCII) and UTF-8 (H5T_CSET_UTF8). |
| H5T_str_t H5Tget_strpad (hid_t type) | The string datatype has a fixed length, but the string may be shorter than the length. This property defines the storage mechanism for the left over bytes. The options are: |
| API Function | Description |
|---|---|
| char* H5Tget_tag(hid_t type_id) | A user-defined string. |
The composite datatype classes can also be analyzed to discover their datatype properties and the datatypes that are members or base types of the composite datatype. The member or base type can, in turn, be analyzed. The table below lists the functions that can access the datatype properties of the different composite datatypes.
| API Function | Description |
|---|---|
| int H5Tget_nmembers(hid_t type_id) | (COMPOUND)The number of fields in the compound datatype. |
| H5T_class_t H5Tget_member_class (hid_t cdtype_id, unsigned member_no) | (COMPOUND)The datatype class of compound datatype member member_no. |
| char* H5Tget_member_name (hid_t type_id, unsigned field_idx) | (COMPOUND)The name of field field_idx of a compound datatype. |
| size_t H5Tget_member_offset (hid_t type_id, unsigned memb_no) | (COMPOUND)The byte offset of the beginning of a field within a compound datatype. |
| hid_t H5Tget_member_type (hid_t type_id, unsigned field_idx) | (COMPOUND)The datatype of the specified member. |
| int H5Tget_array_ndims (hid_t adtype_id) | (ARRAY)The number of dimensions (rank) of the array datatype object. |
| int H5Tget_array_dims (hid_t adtype_id, hsize_t *dims[]) | (ARRAY)The sizes of the dimensions and the dimension permutations of the array datatype object. |
| hid_t H5Tget_super(hid_t type) | (ARRAY, VL, ENUM)The base datatype from which the datatype type is derived. |
| herr_t H5Tenum_nameof(hid_t type, const void *value, char *name, size_t size) | (ENUM)The symbol name that corresponds to the specified value of the enumeration datatype. |
| herr_t H5Tenum_valueof(hid_t type, const char *name, void *value) | (ENUM)The value that corresponds to the specified name of the enumeration datatype. |
| herr_t H5Tget_member_value (hid_t type unsigned memb_no, void *value) | (ENUM)The value of the enumeration datatype member memb_no. |
The HDF5 library enables user programs to create and modify datatypes. The essential steps are:
To create a user-defined atomic datatype, the procedure is to clone a predefined datatype of the appropriate datatype class (H5Tcopy), and then set the datatype properties appropriate to the datatype class. The table below shows how to create a datatype to describe a 1024-bit unsigned integer.
Create a new datatype
Composite datatypes are created with a specific API call for each datatype class. The table below shows the creation method for each datatype class. A newly created datatype cannot be used until the datatype properties are set. For example, a newly created compound datatype has no members and cannot be used.
| Datatype Class | Function to Create |
|---|---|
| COMPOUND | H5Tcreate |
| OPAQUE | H5Tcreate |
| ENUM | H5Tenum_create |
| ARRAY | H5Tarray_create |
| VL | H5Tvlen_create |
Once the datatype is created and the datatype properties set, the datatype object can be used.
Predefined datatypes are defined by the library during initialization using the same mechanisms as described here. Each predefined datatype is locked (H5Tlock), so that it cannot be changed or destroyed. User-defined datatypes may also be locked using H5Tlock.
Table 15 summarizes the API methods that set properties of atomic types. Table 16 shows properties specific to numeric types, Table 17 shows properties specific to the string datatype class. Note that offset, pad, etc. do not apply to strings. Table 18 shows the specific property of the OPAQUE datatype class.
| Functions | Description |
|---|---|
| herr_t H5Tset_size (hid_t type, size_t size) | Set the total size of the element in bytes. This includes padding which may appear on either side of the actual value. If this property is reset to a smaller value which would cause the significant part of the data to extend beyond the edge of the datatype, then the offset property is decremented a bit at a time. If the offset reaches zero and the significant part of the data still extends beyond the edge of the datatype then the precision property is decremented a bit at a time. Decreasing the size of a datatype may fail if the H5T_FLOAT bit fields would extend beyond the significant part of the type. |
| herr_t H5Tset_order (hid_t type, H5T_order_t order) | Set the byte order to little-endian (H5T_ORDER_LE) or big-endian (H5T_ORDER_BE). |
| herr_t H5Tset_precision (hid_t type, size_t precision) | Set the number of significant bits of a datatype. The offset property (defined below) identifies its location. The size property defined above represents the entire size (in bytes) of the datatype. If the precision is decreased then padding bits are inserted on the MSB side of the significant bits (this will fail for H5T_FLOAT types if it results in the sign,mantissa, or exponent bit field extending beyond the edge of the significant bit field). On the other hand, if the precision is increased so that it “hangs over” the edge of the total size then the offset property is decremented a bit at a time. If the offset reaches zero and the significant bits still hang over the edge, then the total size is increased a byte at a time. |
| herr_t H5Tset_offset (hid_t type, size_t offset) | Set the bit location of the least significant bit of a bit field whose length is precision. The bits of the entire data are numbered beginning at zero at the least significant bit of the least significant byte (the byte at the lowest memory address for a little-endian type or the byte at the highest address for a big-endian type). The offset property defines the bit location of the least significant bit of a bit field whose length is precision. If the offset is increased so the significant bits “hang over” the edge of the datum, then the size property is automatically incremented. |
| herr_t H5Tset_pad (hid_t type, H5T_pad_t lsb, H5T_pad_t msb) | Set the padding to zeros (H5T_PAD_ZERO) or ones (H5T_PAD_ONE). Padding is the bits of a data element which are not significant as defined by the precision and offset properties. Padding in the low-numbered bits is lsb padding and padding in the high-numbered bits is msb padding. |
| Functions | Description |
|---|---|
| herr_t H5Tset_sign (hid_t type, H5T_sign_t sign) | (INTEGER)Integer data can be signed two's complement (H5T_SGN_2) or unsigned (H5T_SGN_NONE). |
| herr_t H5Tset_fields (hid_t type, size_t spos, size_t epos, size_t esize, size_t mpos, size_t msize) | (FLOAT)Set the properties define the location (bit position of least significant bit of the field) and size (in bits) of each field. The sign bit is always of length one and none of the fields are allowed to overlap. |
| herr_t H5Tset_ebias (hid_t type, size_t ebias) | (FLOAT)The exponent is stored as a non-negative value which is ebias larger than the true exponent. |
| herr_t H5Tset_norm (hid_t type, H5T_norm_t norm) | (FLOAT)This property describes the normalization method of the mantissa.
|
| herr_t H5Tset_inpad (hid_t type, H5T_pad_t inpad) | (FLOAT) If any internal bits (that is, bits between the sign bit, the mantissa field, and the exponent field but within the precision field) are unused, then they will be filled according to the value of this property. The padding can be: |
| Functions | Description |
|---|---|
| herr_t H5Tset_size (hid_t type, size_t size) | Set the length of the string, in bytes. The precision is automatically set to 8*size. |
| herr_t H5Tset_precision (hid_t type, size_t precision) | The precision must be a multiple of 8. |
| herr_t H5Tset_cset (hid_t type_id, H5T_cset_t cset) | Two character sets are currently supported:
|
| herr_t H5Tset_strpad (hid_t type_id, H5T_str_t strpad) | The string datatype has a fixed length, but the string may be shorter than the length. This property defines the storage mechanism for the left over bytes. The method used to store character strings differs with the programming language:
|
| Functions | Description |
|---|---|
| herr_t H5Tset_tag (hid_t type_id, const char *tag) | Tags the opaque datatype type_id with an ASCII identifier tag. |
The example below shows how to create a 128-bit little-endian signed integer type. Increasing the precision of a type automatically increases the total size. Note that the proper procedure is to begin from a type of the intended datatype class which in this case is a NATIVE INT.
Create a new 128-bit little-endian signed integer datatype
The figure below shows the storage layout as the type is defined. The H5Tcopy creates a datatype that is the same as H5T_NATIVE_INT. In this example, suppose this is a 32-bit big-endian number (Figure a). The precision is set to 128 bits, which automatically extends the size to 8 bytes (Figure b). Finally, the byte order is set to little-endian (Figure c).
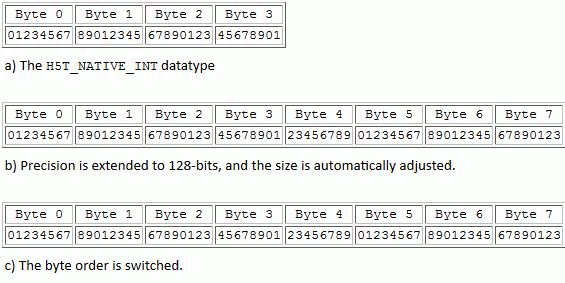
The storage layout for a new 128-bit little-endian signed integer datatype |
The significant bits of a data element can be offset from the beginning of the memory for that element by an amount of padding. The offset property specifies the number of bits of padding that appear to the “right of” the value. The table and figure below show how a 32-bit unsigned integer with 16-bits of precision having the value 0x1122 will be laid out in memory.
| Byte Position | Big-Endian Offset=0 | Big-Endian Offset=16 | Little-Endian Offset=0 | Little-Endian Offset=16 |
|---|---|---|---|---|
| 0: | [pad] | [0x11] | [0x22] | [pad] |
| 1: | [pad] | [0x22] | [0x11] | [pad] |
| 2: | [0x11] | [pad] | [pad] | [0x22] |
| 3: | [0x22] | [pad] | [pad] | [0x11] |
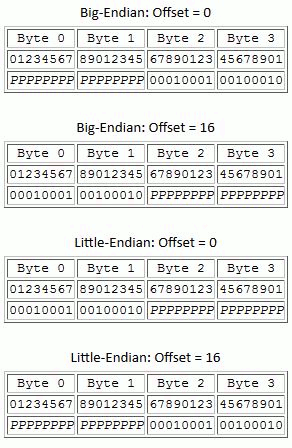
Memory Layout for a 32-bit unsigned integer |
If the offset is incremented then the total size is incremented also if necessary to prevent significant bits of the value from hanging over the edge of the datatype.
The bits of the entire data are numbered beginning at zero at the least significant bit of the least significant byte (the byte at the lowest memory address for a little-endian type or the byte at the highest address for a big-endian type). The offset property defines the bit location of the least significant bit of a bit field whose length is precision. If the offset is increased so the significant bits “hang over” the edge of the datum, then the size property is automatically incremented.
To illustrate the properties of the integer datatype class, the example below shows how to create a user-defined datatype that describes a 24-bit signed integer that starts on the third bit of a 32-bit word. The datatype is specialized from a 32-bit integer, the precision is set to 24 bits, and the offset is set to 3.
A user-defined datatype with a 24-bit signed integer
The figure below shows the storage layout for a data element. Note that the unused bits in the offset will be set to zero and the unused bits at the end will be set to one, as specified in the H5Tset_pad call.
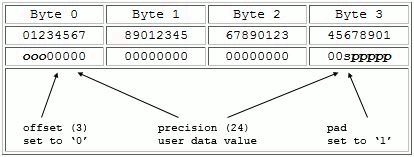
A user-defined integer datatype with a range of -1,048,583 to 1,048,584 |
To illustrate a user-defined floating point number, the example below shows how to create a 24-bit floating point number that starts 5 bits into a 4 byte word. The floating point number is defined to have a mantissa of 19 bits (bits 5-23), an exponent of 3 bits (25-27), and the sign bit is bit 28. (Note that this is an illustration of what can be done and is not necessarily a floating point format that a user would require.)
A user-defined datatype with a 24-bit floating point datatype
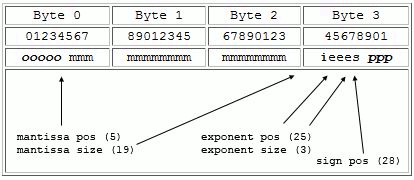
A user-defined floating point datatype |
The figure above shows the storage layout of a data element for this datatype. Note that there is an unused bit (24) between the mantissa and the exponent. This bit is filled with the inpad value which in this case is 0.
The sign bit is always of length one and none of the fields are allowed to overlap. When expanding a floating-point type one should set the precision first; when decreasing the size one should set the field positions and sizes first.
All composite datatypes must be user-defined; there are no predefined composite datatypes.
The subsections below describe how to create a compound datatype and how to write and read data of a compound datatype.
Compound datatypes are conceptually similar to a C struct or Fortran derived types. The compound datatype defines a contiguous sequence of bytes, which are formatted using one up to 2^16 datatypes (members). A compound datatype may have any number of members, in any order, and the members may have any datatype, including compound. Thus, complex nested compound datatypes can be created. The total size of the compound datatype is greater than or equal to the sum of the size of its members, up to a maximum of 2^32 bytes. HDF5 does not support datatypes with distinguished records or the equivalent of C unions or Fortran EQUIVALENCE statements.
Usually a C struct or Fortran derived type will be defined to hold a data point in memory, and the offsets of the members in memory will be the offsets of the struct members from the beginning of an instance of the struct. The HDF5 C library provides a macro HOFFSET (s,m)to calculate the member's offset. The HDF5 Fortran applications have to calculate offsets by using sizes of members datatypes and by taking in consideration the order of members in the Fortran derived type.
This macro computes the offset of member m within a struct s
This macro defined in stddef.h does exactly the same thing as the HOFFSET()macro.
Note for Fortran users: Offsets of Fortran structure members correspond to the offsets within a packed datatype (see explanation below) stored in an HDF5 file.
Each member of a compound datatype must have a descriptive name which is the key used to uniquely identify the member within the compound datatype. A member name in an HDF5 datatype does not necessarily have to be the same as the name of the member in the C struct or Fortran derived type, although this is often the case. Nor does one need to define all members of the C struct or Fortran derived type in the HDF5 compound datatype (or vice versa).
Unlike atomic datatypes which are derived from other atomic datatypes, compound datatypes are created from scratch. First, one creates an empty compound datatype and specifies its total size. Then members are added to the compound datatype in any order. Each member type is inserted at a designated offset. Each member has a name which is the key used to uniquely identify the member within the compound datatype.
The example below shows a way of creating an HDF5 C compound datatype to describe a complex number. This is a structure with two components, “real” and “imaginary”, and each component is a double. An equivalent C struct whose type is defined by the complex_tstruct is shown.
A compound datatype for complex numbers in C
The example below shows a way of creating an HDF5 Fortran compound datatype to describe a complex number. This is a Fortran derived type with two components, “real” and “imaginary”, and each component is DOUBLE PRECISION. An equivalent Fortran TYPE whose type is defined by the TYPE complex_t is shown.
A compound datatype for complex numbers in Fortran
Important Note: The compound datatype is created with a size sufficient to hold all its members. In the C example above, the size of the C struct and the HOFFSET macro are used as a convenient mechanism to determine the appropriate size and offset. Alternatively, the size and offset could be manually determined: the size can be set to 16 with “real” at offset 0 and “imaginary” at offset 8. However, different platforms and compilers have different sizes for “double” and may have alignment restrictions which require additional padding within the structure. It is much more portable to use the HOFFSET macro which assures that the values will be correct for any platform.
The figure below shows how the compound datatype would be laid out assuming that NATIVE_DOUBLE are 64-bit numbers and that there are no alignment requirements. The total size of the compound datatype will be 16 bytes, the “real” component will start at byte 0, and “imaginary” will start at byte 8.
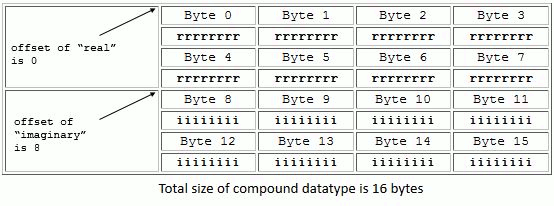
Layout of a compound datatype |
The members of a compound datatype may be any HDF5 datatype including the compound, array, and variable-length (VL) types. The figure and example below show the memory layout and code which creates a compound datatype composed of two complex values, and each complex value is also a compound datatype as in the figure above.
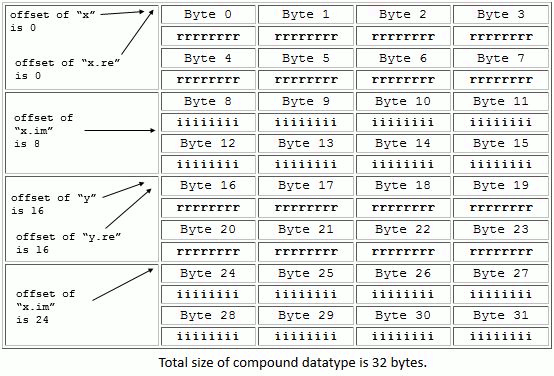
Layout of a compound datatype nested in a compound datatype |
TText for a compound datatype nested in a compound datatype
Note that a similar result could be accomplished by creating a compound datatype and inserting four fields. See the figure below. This results in the same layout as the figure above. The difference would be how the fields are addressed. In the first case, the real part of ‘y’ is called ‘y.re’; in the second case it is ‘y-re’.
Another compound datatype nested in a compound datatype
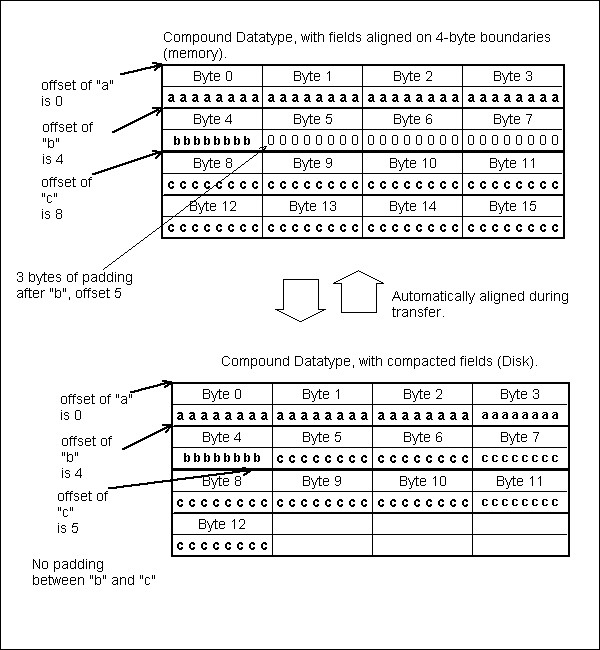
The members of a compound datatype do not always fill all the bytes. The HOFFSET macro assures that the members will be laid out according to the requirements of the platform and language. The example below shows an example of a C struct which requires extra bytes of padding on many platforms. The second element, ‘b’, is a 1-byte character followed by an 8 byte double, ‘c’. On many systems, the 8-byte value must be stored on a 4-or 8-byte boundary. This requires the struct to be larger than the sum of the size of its elements.
In the example below, sizeof and HOFFSET are used to assure that the members are inserted at the correct offset to match the memory conventions of the platform. The figure below shows how this data element would be stored in memory, assuming the double must start on a 4-byte boundary. Notice the extra bytes between ‘b’ and ‘c’.
A compound datatype that requires padding
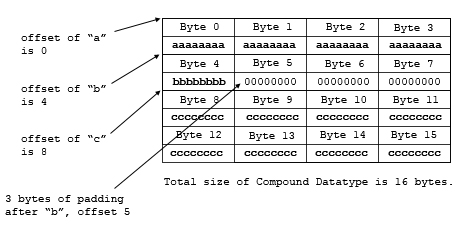
Memory layout of a compound datatype that requires padding |
However, data stored on disk does not require alignment, so unaligned versions of compound data structures can be created to improve space efficiency on disk. These unaligned compound datatypes can be created by computing offsets by hand to eliminate inter-member padding, or the members can be packed by calling H5Tpack (which modifies a datatype directly, so it is usually preceded by a call to H5Tcopy).
The example below shows how to create a disk version of the compound datatype from the figure above in order to store data on disk in as compact a form as possible. Packed compound datatypes should generally not be used to describe memory as they may violate alignment constraints for the architecture being used. Note also that using a packed datatype for disk storage may involve a higher data conversion cost.
Create a packed compound datatype in C
The example below shows the sequence of Fortran calls to create a packed compound datatype. An HDF5 Fortran compound datatype never describes a compound datatype in memory and compound data is ALWAYS written by fields as described in the next section. Therefore packing is not needed unless the offset of each consecutive member is not equal to the sum of the sizes of the previous members.
Create a packed compound datatype in Fortran
Creating datasets with compound datatypes is similar to creating datasets with any other HDF5 datatypes. But writing and reading may be different since datasets that have compound datatypes can be written or read by a field (member) or subsets of fields (members). The compound datatype is the only composite datatype that supports “sub-setting” by the elements the datatype is built from.
The example below shows a C example of creating and writing a dataset with a compound datatype.
Create and write a dataset with a compound datatype in C
The example below shows the content of the file written on a little-endian machine.
Create and write a little-endian dataset with a compound datatype in C
It is not necessary to write the whole data at once. Datasets with compound datatypes can be written by field or by subsets of fields. In order to do this one has to remember to set the transfer property of the dataset using the H5Pset_preserve call and to define the memory datatype that corresponds to a field. The example below shows how float and double fields are written to the dataset.
Writing floats and doubles to a dataset
The figure below shows the content of the file written on a little-endian machine. Only float and double fields are written. The default fill value is used to initialize the unwritten integer field.
Writing floats and doubles to a dataset on a little-endian system
The example below contains a Fortran example that creates and writes a dataset with a compound datatype. As this example illustrates, writing and reading compound datatypes in Fortran is always done by fields. The content of the written file is the same as shown in the example above.
Create and write a dataset with a compound datatype in Fortran
Reading datasets with compound datatypes may be a challenge. For general applications there is no way to know a priori the corresponding C structure. Also, C structures cannot be allocated on the fly during discovery of the dataset's datatype. For general C, C++, Fortran and Java application the following steps will be required to read and to interpret data from the dataset with compound datatype:
The examples below show how to read a dataset with a known compound datatype.
The first example below shows the steps needed to read data of a known structure. First, build a memory datatype the same way it was built when the dataset was created, and then second use the datatype in an H5Dread call.
Read a dataset using a memory datatype
Instead of building a memory datatype, the application could use the H5Tget_native_type function. See the example below.
Read a dataset using H5Tget_native_type
The example below shows how to read just one float member of a compound datatype.
Read one floating point member of a compound datatype
The example below shows how to read float and double members of a compound datatype into a structure that has those fields in a different order. Please notice that H5Tinsert calls can be used in an order different from the order of the structure's members.
Read float and double members of a compound datatype
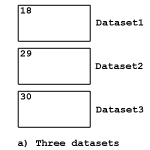
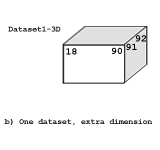
Many scientific datasets have multiple measurements for each point in a space. There are several natural ways to represent this data, depending on the variables and how they are used in computation. See the table and the figure below.
|
Storage Strategy |
Stored as |
Remarks |
|---|---|---|
| Multiple planes | Several datasets with identical dataspaces | This is optimal when variables are accessed individually, or when often uses only selected variables. |
| Additional dimension | One dataset, the last “dimension” is a vec-tor of variables | This can give good performance, although selecting only a few variables may be slow. This may not reflect the science. |
| Record with multiple values | One dataset with compound datatype | This enables the variables to be read all together or selected. Also handles “vectors” of heterogeneous data. |
| Vector or Tensor value | One dataset, each data element is a small array of values. | This uses the same amount of space as the previous two, and may represent the science model better. |
| 
|

| 
|
The HDF5 H5T_ARRAY datatype defines the data element to be a homogeneous, multi-dimensional array. See Figure 13 above. The elements of the array can be any HDF5 datatype (including compound and array), and the size of the datatype is the total size of the array. A dataset of array datatype cannot be subdivided for I/O within the data element: the entire array of the data element must be transferred. If the data elements need to be accessed separately, for example, by plane, then the array datatype should not be used. The table below shows advantages and disadvantages of various storage methods.
|
Method |
Advantages |
Disadvantages |
|---|---|---|
| Multiple Datasets | Easy to access each plane, can select any plane(s) | Less efficient to access a ‘column’ through the planes |
| N+1 Dimension | All access patterns supported | Must be homogeneous datatype The added dimension may not make sense in the scientific model |
| Compound Datatype | Can be heterogeneous datatype | Planes must be named, selection is by plane Not a natural representation for a matrix |
| Array | A natural representation for vector or tensor data | Cannot access elements separately (no access by plane) |
An array datatype may be multi-dimensional with 1 to H5S_MAX_RANK (the maximum rank of a dataset is currently 32) dimensions. The dimensions can be any size greater than 0, but unlimited dimensions are not supported (although the datatype can be a variable-length datatype).
An array datatype is created with the H5Tarray_create call, which specifies the number of dimensions, the size of each dimension, and the base type of the array. The array datatype can then be used in any way that any datatype object is used. The example below shows the creation of a datatype that is a two-dimensional array of native integers, and this is then used to create a dataset. Note that the dataset can be a dataspace that is any number and size of dimensions. The figure below shows the layout in memory assuming that the native integers are 4 bytes. Each data element has 6 elements, for a total of 24 bytes.
Create a two-dimensional array datatype
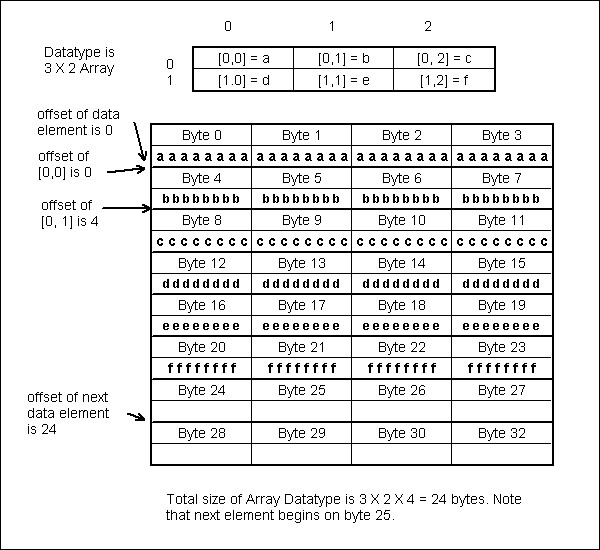
Memory layout of a two-dimensional array datatype |
A variable-length (VL) datatype is a one-dimensional sequence of a datatype which are not fixed in length from one dataset location to another. In other words, each data element may have a different number of members. Variable-length datatypes cannot be divided; the entire data element must be transferred.
VL datatypes are useful to the scientific community in many different ways, possibly including:
A VL datatype is created by calling H5Tvlen_create which specifies the base datatype. The first example below shows an example of code that creates a VL datatype of unsigned integers. Each data element is a one-dimensional array of zero or more members and is stored in the hvl_t structure. See the second example below.
Create a variable-length datatype of unsigned integers
Data element storage for members of the VL datatype
The first example below shows how the VL data is written. For each of the 10 data elements, a length and data buffer must be allocated. Below the two examples is a figure that shows how the data is laid out in memory.
An analogous procedure must be used to read the data. See the second example below. An appropriate array of hvl_t must be allocated, and the data read. It is then traversed one data element at a time. The H5Treclaim call frees the data buffer for the buffer. With each element possibly being of different sequence lengths for a dataset with a VL datatype, the memory for the VL datatype must be dynamically allocated. Currently there are two methods of managing the memory for VL datatypes: the standard C malloc/free memory allocation routines or a method of calling user-defined memory management routines to allocate or free memory (set with H5Pset_vlen_mem_manager). Since the memory allocated when reading (or writing) may be complicated to release, the H5Treclaim function is provided to traverse a memory buffer and free the VL datatype information without leaking memory.
Write VL data
Read VL data
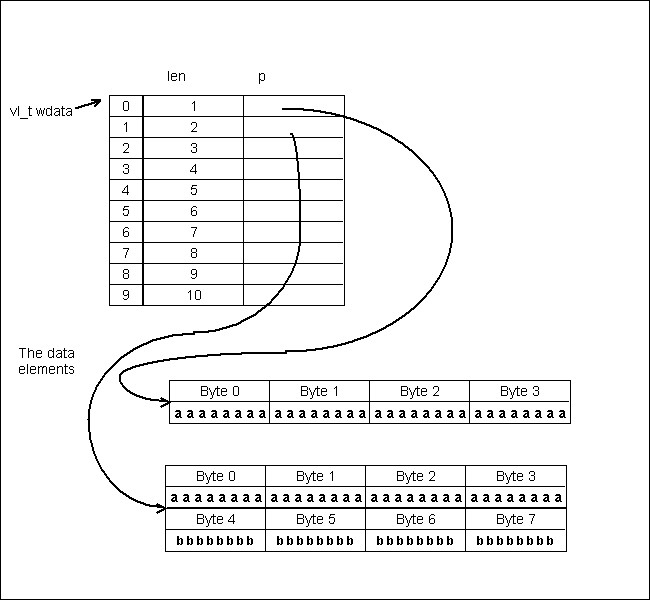
Memory layout of a VL datatype |
The user program must carefully manage these relatively complex data structures. The H5Treclaim function performs a standard traversal, freeing all the data. This function analyzes the datatype and dataspace objects, and visits each VL data element, recursing through nested types. By default, the system free is called for the pointer in each hvl_t. Obviously, this call assumes that all of this memory was allocated with the system malloc.
The user program may specify custom memory manager routines, one for allocating and one for freeing. These may be set with the H5Pset_vlen_mem_manager, and must have the following prototypes:
The utility function H5Dvlen_get_buf_size checks the number of bytes required to store the VL data from the dataset. This function analyzes the datatype and dataspace object to visit all the VL data elements, to determine the number of bytes required to store the data for the in the destination storage (memory). The size value is adjusted for data conversion and alignment in the destination.
Several datatype classes define special types of objects.
Text data is represented by arrays of characters, called strings. Many programming languages support different conventions for storing strings, which may be fixed or variable-length, and may have different rules for padding unused storage. HDF5 can represent strings in several ways. See the figure below.
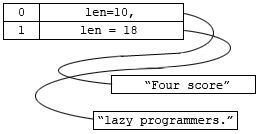
The strings to store are “Four score” and “lazy programmers.”
| a) H5T_NATIVE_CHAR: The dataset is a one-dimensional array with 29 elements, and each element is a single character. |

|
| b) Fixed-length string: The dataset is a one-dimensional array with two elements, and each element is 20 characters. |

|
| c) Variable-length string: The dataset is a one-dimensional array with two elements, and each element is a variable-length string. This is the same result when stored as a fixed-length string except that the first element of the array will need only 11 bytes for storage instead of 20. |

|
|
First, a dataset may have a dataset with datatype H5T_NATIVE_CHAR with each character of the string as an element of the dataset. This will store an unstructured block of text data, but gives little indication of any structure in the text. See item a in the figure above.
A second alternative is to store the data using the datatype class H5T_STRING with each element a fixed length. See item b in the figure above. In this approach, each element might be a word or a sentence, addressed by the dataspace. The dataset reserves space for the specified number of characters, although some strings may be shorter. This approach is simple and usually is fast to access, but can waste storage space if the length of the Strings varies.
A third alternative is to use a variable-length datatype. See item c in the figure above. This can be done using the standard mechanisms described above. The program would use hvl_t structures to write and read the data.
A fourth alternative is to use a special feature of the string datatype class to set the size of the datatype to H5T_VARIABLE. See item c in the figure above. The example below shows a declaration of a datatype of type H5T_C_S1 which is set to H5T_VARIABLE. The HDF5 Library automatically translates between this and the hvl_t structure. Note: the H5T_VARIABLE size can only be used with string datatypes.
Set the string datatype size to H5T_VARIABLE
Variable-length strings can be read into C strings (in other words, pointers to zero terminated arrays of char). See the example below.
Read variable-length strings into C strings
In HDF5, objects (groups, datasets, attributes, and committed datatypes) are usually accessed by name. There is another way to access stored objects - by reference. Before HDF5 1.12.0, there were only two reference datatypes: object reference and region reference. Since 1.12.0, attribute references and external references were added. And all references can be stored and retrieved from a file by invoking the H5Dwrite and H5Dread functions with a single predefined type: H5T_STD_REF.
The first example below shows an example of code that creates references to four objects, and then writes the array of object references to a dataset. The second example below shows a dataset of datatype reference being read and one of the reference objects being dereferenced to obtain an object pointer.
Create object references and write to a dataset
Read a dataset with a reference datatype
In HDF5, objects (groups, datasets, and committed datatypes) are usually accessed by name. There is another way to access stored objects - by reference. There are two deprecated reference datatypes: object reference and region reference. Object reference objects are created with H5Rcreate and other calls (cross reference). These objects can be stored and retrieved in a dataset as elements with reference datatype. The first example below shows an example of code that creates references to four objects, and then writes the array of object references to a dataset. The second example below shows a dataset of datatype reference being read and one of the reference objects being dereferenced to obtain an object pointer.
In order to store references to regions of a dataset, the datatype should be H5T_STD_REF_DSETREG. Note that a data element must be either an object reference or a region reference: these are different types and cannot be mixed within a single array.
A reference datatype cannot be divided for I/O: an element is read or written completely.
Create object references and write to a dataset
Read a dataset with a reference datatype
The enum datatype implements a set of (name, value) pairs, similar to C/C++ enum. The values are currently limited to native integer datatypes. Each name can be the name of only one value, and each value can have only one name.
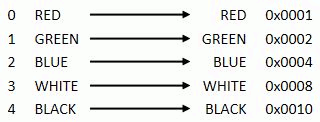
The data elements of the ENUMERATION are stored according to the datatype. An example would be as an array of integers. The example below shows an example of how to create an enumeration with five elements. The elements map symbolic names to 2-byte integers. See the table below.
Create an enumeration with five elements
| Name | Value |
|---|---|
| RED | 0 |
| GREEN | 1 |
| BLUE | 2 |
| WHITE | 3 |
| BLACK | 4 |
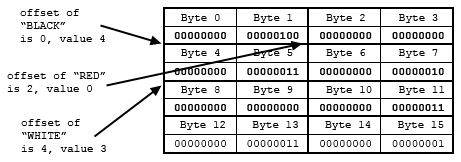
The figure below shows how an array of eight values might be stored. Conceptually, the array is an array of symbolic names [BLACK, RED, WHITE, BLUE, ...] See item a in the figure below. These are stored as the values and are short integers. So, the first 2 bytes are the value associated with “BLACK”, which is the number 4, and so on. See item b in the figure below.
| a) Logical data to be written - eight elements |

|
| b) The storage layout. Total size of the array is 16 bytes, 2 bytes per element. |
|
The order that members are inserted into an enumeration type is unimportant; the important part is the associations between the symbol names and the values. Thus, two enumeration datatypes will be considered equal if and only if both types have the same symbol/value associations and both have equal underlying integer datatypes. Type equality is tested with the H5Tequal function.
If a particular architecture type is required, a little-endian or big-endian datatype for example, use a native integer datatype as the ENUM base datatype and use H5Tconvert on values as they are read from or written to a dataset.
In some cases, a user may have data objects that should be stored and retrieved as blobs with no attempt to interpret them. For example, an application might wish to store an array of encrypted certificates which are 100 bytes long.
While an arbitrary block of data may always be stored as bytes, characters, integers, or whatever, this might mislead programs about the meaning of the data. The opaque datatype defines data elements which are uninterpreted by HDF5. The opaque data may be labeled with H5Tset_tag with a string that might be used by an application. For example, the encrypted certificates might have a tag to indicate the encryption and the certificate standard.
Some data is represented as bits, where the number of bits is not an integral byte and the bits are not necessarily interpreted as a standard type. Some examples might include readings from machine registers (for example, switch positions), a cloud mask, or data structures with several small integers that should be store in a single byte.
This data could be stored as integers, strings, or enumerations. However, these storage methods would likely result in considerable wasted space. For example, storing a cloud mask with one byte per value would use up to eight times the space of a packed array of bits.
The HDF5 bitfield datatype class defines a data element that is a contiguous sequence of bits, which are stored on disk in a packed array. The programming model is the same as for unsigned integers: the datatype object is created by copying a predefined datatype, and then the precision, offset, and padding are set.
While the use of the bitfield datatype will reduce storage space substantially, there will still be wasted space if the bitfield as a whole does not match the 1-, 2-, 4-, or 8-byte unit in which it is written. The remaining unused space can be removed by applying the N-bit filter to the dataset containing the bitfield data. For more information, see "Using the N-bit Filter."
The “fill value” for a dataset is the specification of the default value assigned to data elements that have not yet been written. In the case of a dataset with an atomic datatype, the fill value is a single value of the appropriate datatype, such as ‘0’ or ‘-1.0’. In the case of a dataset with a composite datatype, the fill value is a single data element of the appropriate type. For example, for an array or compound datatype, the fill value is a single data element with values for all the component elements of the array or compound datatype.
The fill value is set (permanently) when the dataset is created. The fill value is set in the dataset creation properties in the H5Dcreate call. Note that the H5Dcreate call must also include the datatype of the dataset, and the value provided for the fill value will be interpreted as a single element of this datatype. The example below shows code which creates a dataset of integers with fill value -1. Any unwritten data elements will be set to -1.
Create a dataset with a fill value of -1
Create a fill value for a compound datatype
The code above shows how to create a fill value for a compound datatype. The procedure is the same as the previous example except the filler must be a structure with the correct fields. Each field is initialized to the desired fill value.
The fill value for a dataset can be retrieved by reading the dataset creation properties of the dataset and then by reading the fill value with H5Pget_fill_value. The data will be read into memory using the storage layout specified by the datatype. This transfer will convert data in the same way as H5Dread. The example below shows how to get the fill value from the dataset created in the example "Create a dataset with a fill value of -1".
Retrieve a fill value
A similar procedure is followed for any datatype. The example below shows how to read the fill value for the compound datatype created in an example above. Note that the program must pass an element large enough to hold a fill value of the datatype indicated by the argument to H5Pget_fill_value. Also, the program must understand the datatype in order to interpret its components. This may be difficult to determine without knowledge of the application that created the dataset.
Read the fill value for a compound datatype
Several composite datatype classes define collections of other datatypes, including other composite datatypes. In general, a datatype can be nested to any depth, with any combination of datatypes.
For example, a compound datatype can have members that are other compound datatypes, arrays, VL datatypes. An array can be an array of array, an array of compound, or an array of VL. And a VL datatype can be a variable-length array of compound, array, or VL datatypes.
These complicated combinations of datatypes form a logical tree, with a single root datatype, and leaves which must be atomic datatypes (predefined or user-defined). The figure below shows an example of a logical tree describing a compound datatype constructed from different datatypes.
Recall that the datatype is a description of the layout of storage. The complicated compound datatype is constructed from component datatypes, each of which describes the layout of part of the storage. Any datatype can be used as a component of a compound datatype, with the following restrictions:
These restrictions are essentially the rules for C structures and similar record types familiar from programming languages. Multiple typing, such as a C union, is not allowed in HDF5 datatypes.
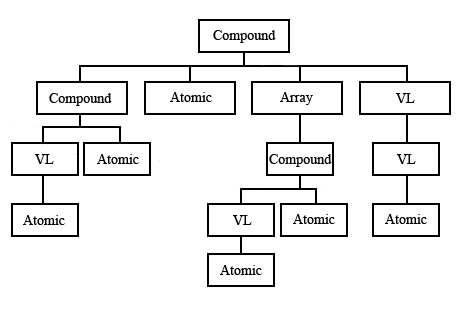
A compound datatype built with different datatypes |
To construct a complicated compound datatype, each component is constructed, and then added to the enclosing datatype description. The example below shows how to create a compound datatype with four members:
Below the example code is a figure that shows this datatype as a logical tree. The output of the h5dump utility is shown in the example below the figure.
Each datatype is created as a separate datatype object. Figure "The storage layout for the four member datatypes" below shows the storage layout for the four individual datatypes. Then the datatypes are inserted into the outer datatype at an appropriate offset. Figure "The storage layout of the combined four members" below shows the resulting storage layout. The combined record is 89 bytes long.
The Dataset is created using the combined compound datatype. The dataset is declared to be a 4 by 3 array of compound data. Each data element is an instance of the 89-byte compound datatype. Figure "The layout of the dataset" below shows the layout of the dataset, and expands one of the elements to show the relative position of the component data elements.
Each data element is a compound datatype, which can be written or read as a record, or each field may be read or written individually. The first field (“T1”) is itself a compound datatype with three fields (“T1.a”, “T1.b”, and “T1.c”). “T1” can be read or written as a record, or individual fields can be accessed. Similarly, the second filed is a compound datatype with two fields (“T2.f1”, “T2.f2”).
The third field (“T3”) is an array datatype. Thus, “T3” should be accessed as an array of 40 integers. Array data can only be read or written as a single element, so all 40 integers must be read or written to the third field. The fourth field (“T4”) is a single string of length 25.
Create a compound datatype with four members
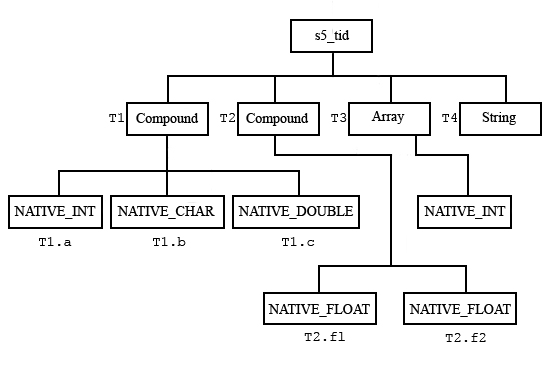
Logical tree for the compound datatype with four members |
Output from h5dump for the compound datatype
| a) Compound type ‘s1_t’, size 16 bytes. |

|
| b) Compound type ‘s2_t’, size 8 bytes. |

|
| c) Array type ‘s3_tid’, 40 integers, total size 40 bytes. |
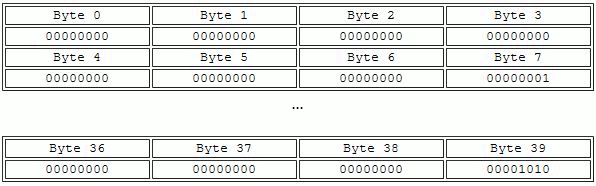
|
| d) String type ‘s4_tid’, size 25 bytes. |
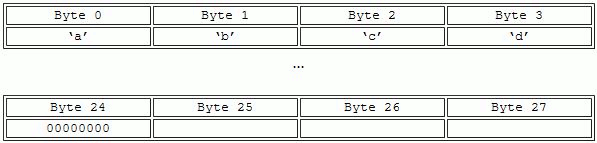
|
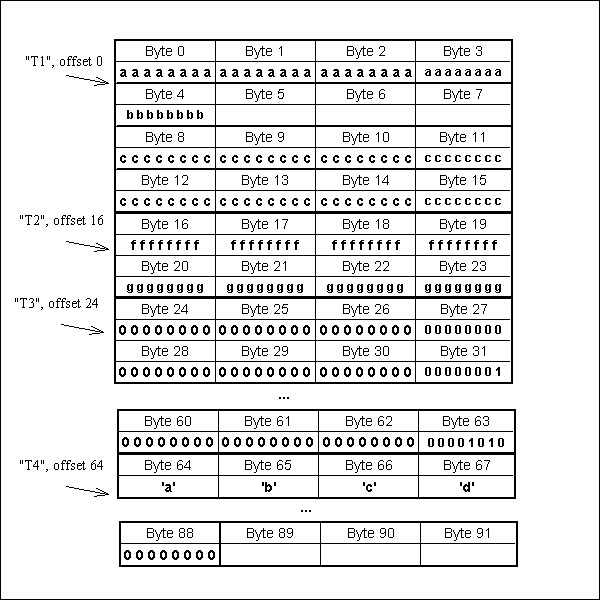
The storage layout of the combined four members |
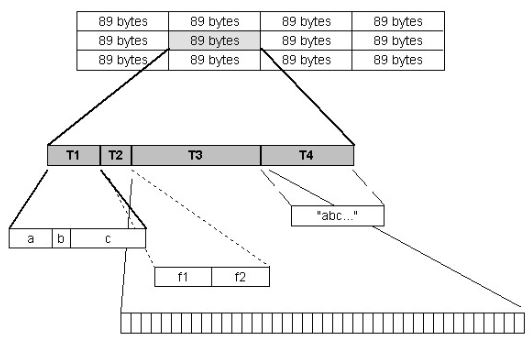
The layout of the dataset |
A complicated compound datatype can be analyzed piece by piece to discover the exact storage layout. In the example above, the outer datatype is analyzed to discover that it is a compound datatype with four members. Each member is analyzed in turn to construct a complete map of the storage layout.
The example below shows an example of code that partially analyzes a nested compound datatype. The name and overall offset and size of the component datatype is discovered, and then its type is analyzed depending on the datatype class. Through this method, the complete storage layout can be discovered.
Output from h5dump for the compound datatype
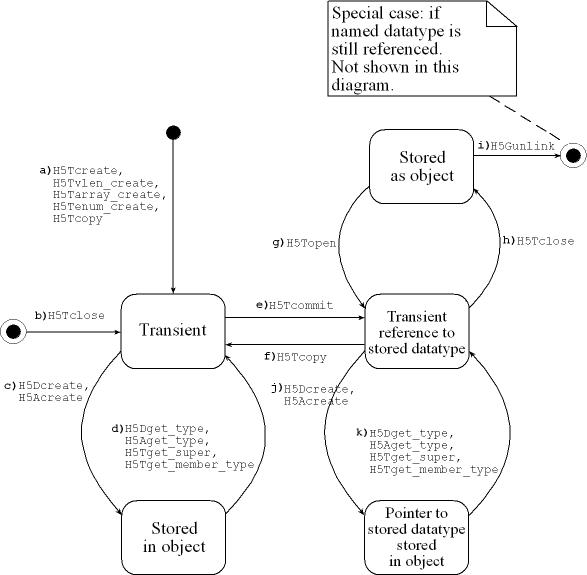
Application programs access HDF5 datatypes through identifiers. Identifiers are obtained by creating a new datatype or by copying or opening an existing datatype. The identifier can be used until it is closed or until the library shuts down. See items a and b in the figure below. By default, a datatype is transient, and it disappears when it is closed.
When a dataset or attribute is created (H5Dcreate or H5Acreate), its datatype is stored in the HDF5 file as part of the dataset or attribute object. See item c in the figure below. Once an object created, its datatype cannot be changed or deleted. The datatype can be accessed by calling H5Dget_type, H5Aget_type, H5Tget_super, or H5Tget_member_type. See item d in the figure below. These calls return an identifier to a transient copy of the datatype of the dataset or attribute unless the datatype is a committed datatype. Note that when an object is created, the stored datatype is a copy of the transient datatype. If two objects are created with the same datatype, the information is stored in each object with the same effect as if two different datatypes were created and used.
A transient datatype can be stored using H5Tcommit in the HDF5 file as an independent, named object, called a committed datatype. Committed datatypes were formerly known as named datatypes. See item e in the figure below. Subsequently, when a committed datatype is opened with H5Topen (item f), or is obtained with H5Tget_member_type or similar call (item k), the return is an identifier to a transient copy of the stored datatype. The identifier can be used in the same way as other datatype identifiers except that the committed datatype cannot be modified. When a committed datatype is copied with H5Tcopy, the return is a new, modifiable, transient datatype object (item f).
When an object is created using a committed datatype (H5Dcreate, H5Acreate), the stored datatype is used without copying it to the object. See item j in the figure below. In this case, if multiple objects are created using the same committed datatype, they all share the exact same datatype object. This saves space and makes clear that the datatype is shared. Note that a committed datatype can be shared by objects within the same HDF5 file, but not by objects in other files. For more information on copying committed datatypes to other HDF5 files, see the “Copying Committed Datatypes with H5Ocopy” topic in the “Additional Resources” chapter.
A committed datatype can be deleted from the file by calling H5Ldelete which replaces H5Gunlink. See item i in the figure below. If one or more objects are still using the datatype, the committed datatype cannot be accessed with H5Topen, but will not be removed from the file until it is no longer used. H5Tget_member_type and similar calls will return a transient copy of the datatype.
Life cycle of a datatype |
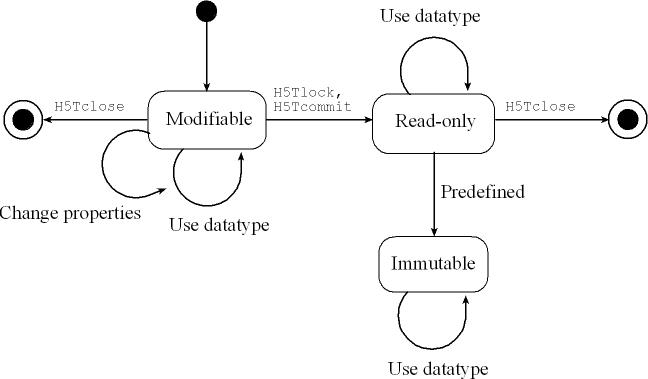
Transient datatypes are initially modifiable. Note that when a datatype is copied or when it is written to the file (when an object is created) or the datatype is used to create a composite datatype, a copy of the current state of the datatype is used. If the datatype is then modified, the changes have no effect on datasets, attributes, or datatypes that have already been created. See the figure below.
A transient datatype can be made read-only (H5Tlock). Note that the datatype is still transient, and otherwise does not change. A datatype that is immutable is read-only but cannot be closed except when the entire library is closed. The predefined types such as H5T_NATIVE_INT are immutable transient types.
Transient datatype states: modifiable, read-only, and immutable |
To create two or more datasets that share a common datatype, first commit the datatype, and then use that datatype to create the datasets. See the example below.
Create a shareable datatype
| Function | Description |
|---|---|
| A committed datatype can be opened by calling this function, which returns a datatype identifier. The identifier should eventually be released by calling H5Tclose() to release resources. The committed datatype returned by this function is read-only or a negative value is returned for failure. The location is either a file or group identifier. | |
herr_t H5Tcommit (hid_t location, const char *name, hid_t type, H5P_DEFAULT, H5P_DEFAULT, H5P_DEFAULT)
| A transient datatype (not immutable) can be written to a file and turned into a committed datatype by calling this function. The location is either a file or group identifier and when combined with name refers to a new committed datatype. |
htri_t H5Tcommitted(hid_t type_id) Determines whether a datatype is a committed type or a transient type. | A type can be queried to determine if it is a committed type or a transient type. If this function returns a positive value then the type is committed. Datasets which return committed datatypes with H5Dget_type() are able to share the datatype with other datasets in the same file. |
When data is transferred (write or read), the storage layout of the data elements may be different. For example, an integer might be stored on disk in big-endian byte order and read into memory with little-endian byte order. In this case, each data element will be transformed by the HDF5 Library during the data transfer.
The conversion of data elements is controlled by specifying the datatype of the source and specifying the intended datatype of the destination. The storage format on disk is the datatype specified when the dataset is created. The datatype of memory must be specified in the library call.
In order to be convertible, the datatype of the source and destination must have the same datatype class (with the exception of enumeration type). Thus, integers can be converted to other integers, and floats to other floats, but integers cannot (yet) be converted to floats. For each atomic datatype class, the possible conversions are defined. An enumeration datatype can be converted to an integer or a floating-point number datatype.
Basically, any datatype can be converted to another datatype of the same datatype class. The HDF5 Library automatically converts all properties. If the destination is too small to hold the source value then an overflow or underflow exception occurs. If a handler is defined with the H5Pset_type_conv_cb function, it will be called. Otherwise, a default action will be performed. The table below summarizes the default actions.
| Datatype Class | Possible Exceptions | Default Action |
|---|---|---|
| Integer | Size, offset, pad | |
| Float | Size, offset, pad, ebits | |
| String | Size | Truncates, zero terminate if required. |
| Enumeration | No field | All bits set |
For example, when reading data from a dataset, the source datatype is the datatype set when the dataset was created, and the destination datatype is the description of the storage layout in memory. The destination datatype must be specified in the H5Dread call. The example below shows an example of reading a dataset of 32-bit integers. The figure below the example shows the data transformation that is performed.
Specify the destination datatype with H5Dread



|
One thing to note in the example above is the use of the predefined native datatype H5T_NATIVE_INT. Recall that in this example, the data was stored as a 4-bytes in big-endian order. The application wants to read this data into an array of integers in memory. Depending on the system, the storage layout of memory might be either big or little-endian, so the data may need to be transformed on some platforms and not on others. The H5T_NATIVE_INT type is set by the HDF5 Library to be the correct type to describe the storage layout of the memory on the system. Thus, the code in the example above will work correctly on any platform, performing a transformation when needed.
There are predefined native types for most atomic datatypes, and these can be combined in composite datatypes. In general, the predefined native datatypes should always be used for data stored in memory. Predefined native datatypes describe the storage properties of memory.
An enum datatype conversion |
Create an aligned and packed compound datatype
Alignment of a compound datatype |
Transfer some fields of a compound datatype
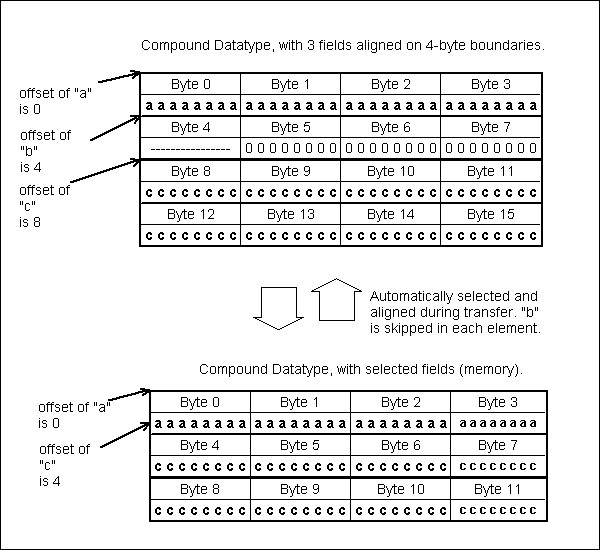
Layout when an element is skipped |
HDF5 provides a means for generating a portable and human-readable text description of a datatype and for generating a datatype from such a text description. This capability is particularly useful for creating complex datatypes in a single step, for creating a text description of a datatype for debugging purposes, and for creating a portable datatype definition that can then be used to recreate the datatype on many platforms or in other applications.
These tasks are handled by two functions provided in the HDF5 Lite high-level library:
Note that this functionality requires that the HDF5 High-Level Library (H5LT) be installed.
While H5LTtext_to_dtype can be used to generate any sort of datatype, it is particularly useful for complex datatypes.
H5LTdtype_to_text is most likely to be used in two sorts of situations: when a datatype must be closely examined for debugging purpose or to create a portable text description of the datatype that can then be used to recreate the datatype on other platforms or in other applications.
These two functions work for all valid HDF5 datatypes except time, bitfield, and reference datatypes.
The currently supported text format used by H5LTtext_to_dtype and H5LTdtype_to_text is the data description language (DDL) and conforms to the DDL in BNF for HDF5 1.14.4 and above. The portion of the DDL in BNF for HDF5 1.14.4 and above that defines HDF5 datatypes appears below.
The definition of HDF5 datatypes from the HDF5 DDL
Old definitions of the opaque and compound datatypes
The code sample below illustrates the use of H5LTtext_to_dtype to generate a variable-length string datatype.
Creating a variable-length string datatype from a text description
The code sample below illustrates the use of H5LTtext_to_dtype to generate a complex array datatype.
Creating a complex array datatype from a text description
Previous Chapter HDF5 Datasets - Next Chapter HDF5 Dataspaces and Partial I/O
