|
HDF5 Last Updated on 2026-06-27
The HDF5 Field Guide
|
|
HDF5 Last Updated on 2026-06-27
The HDF5 Field Guide
|
Navigate back: Main / HDF5 User Guide
The HDF5 Dataset Optimization (H5DO) interface provides high-performance functions for specialized dataset I/O operations that bypass standard HDF5 processing layers when appropriate.
Since version 1.10.3 these functions are deprecated in favor of H5Dwrite_chunk and H5Dread_chunk.
When a user application has a chunked dataset and is trying to write a single chunk of data with H5Dwrite, the data goes through several steps inside the HDF5 library. The library first examines the hyperslab selection. Then it converts the data from the datatype in memory to the datatype in the file if they are different. Finally, the library processes the data in the filter pipeline. Starting with the 1.8.11 release, a new high-level C function called H5DOwrite_chunk becomes available. It writes a data chunk directly to the file bypassing the library’s hyperslab selection, data conversion, and filter pipeline processes. In other words, if an application can pre-process the data, then the application can use H5DOwrite_chunk to write the data much faster.
H5DOwrite_chunk was developed in response to a client request. The client builds X-ray pixel detectors for use at synchrotron light sources. These detectors can produce data at the rate of tens of gigabytes per second. Before transferring the data over their network, the detectors compress the data by a factor of 10 or more. The modular architecture of the detectors can scale up its data stream in parallel and maps well to current parallel computing and storage systems. See the Direct Chunk Write for the original proposal.
Basically, the H5DOwrite_chunk function takes a pre-processed data chunk (buf) and its size (data_size) and writes to the chunk location (offset) in the dataset ( dset_id).
The function prototype is shown below:
Below is a simple example showing how to use the function: Example 1. Using H5DOwrite_chunk
In the example above, the dataset is 8x8 elements of int. Each chunk is 4x4. The offset of the first element of the chunk to be written is 4 and 4. In the diagram below, the shaded chunk is the data to be written. The function is writing a pre-compressed data chunk of 40 bytes (assumed) to the dataset. The zero value of the filter mask means that all filters have been applied to the pre-processed data.
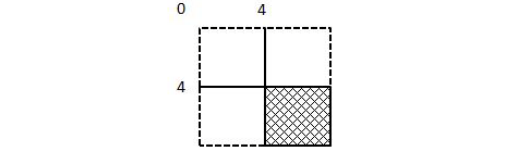
Figure 1. Illustration of the chunk to be written |
The complete code example at the end of this topic shows how to set the value of the filter mask to indicate a filter being skipped. The corresponding bit in the filter mask is turned on when a filter is skipped. For example, if the second filter is skipped, the second bit of the filter mask should be turned on. For more information, see the H5DOwrite_chunk entry in the HDF5 Reference Manual.
The following diagram shows how the function H5DOwrite_chunk bypasses hyperslab selection, data conversion, and filter pipeline inside the HDF5 library.
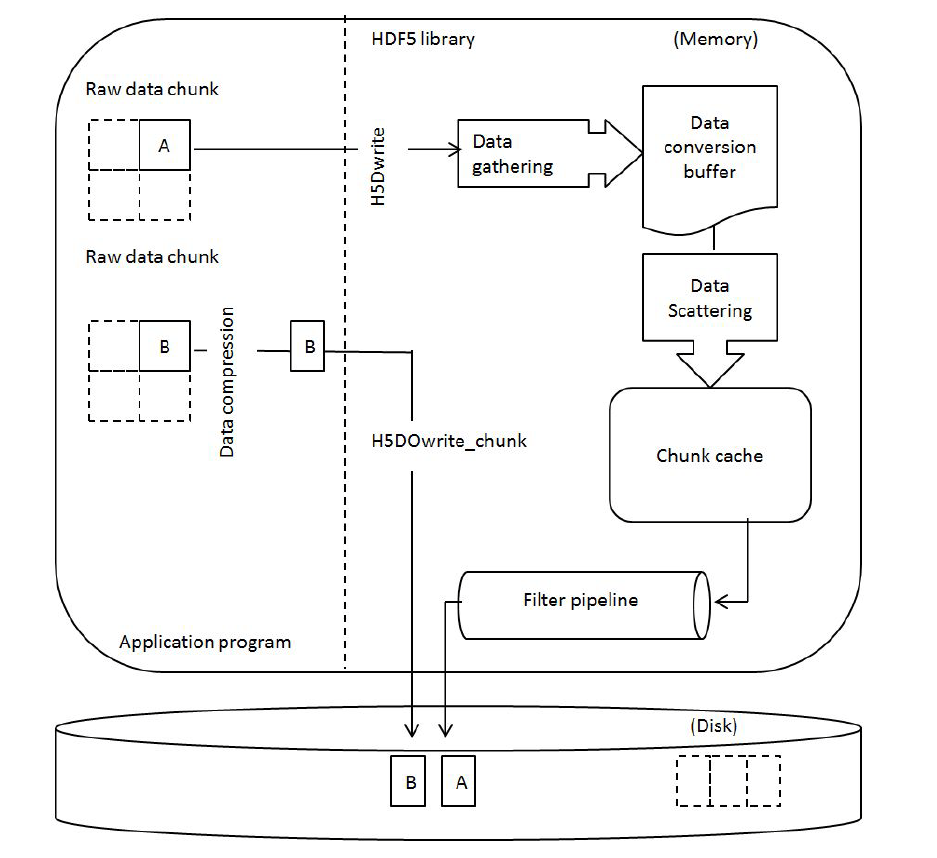
Figure 2. Diagram for H5DOwrite_chunk |
The table below describes the results of performance benchmark tests run by HDF developers. It shows that using the new function H5DOwrite_chunk to write pre-compressed data is much faster than using the H5Dwrite function to compress and write the same data with the filter pipeline. Measurements involving H5Dwrite include compression time in the filter pipeline. Since the data is already compressed before H5DOwrite_chunk is called, use of H5DOwrite_chunk to write compressed data avoids the performance bottleneck in the HDF5 filter pipeline.
The test was run on a Linux 2.6.18 / 64-bit Intel x86_64 machine. The dataset contained 100 chunks. Only one chunk was written to the file per write call. The number of writes was 100. The time measurement was for the entire dataset with the Unix system function gettimeofday. Writing the entire dataset with one write call took almost the same amount of time as writing chunk by chunk. In order to force the system to flush the data to the file, the O_SYNC flag was used to open the file.
Table 1. Performance result for H5DOwrite_chunk in the high-level library
| Dataset size (MB) | 95.37 | 762.94 | 2288.82 | |||
| Size after compression (MB) | 64.14 | 512.94 | 1538.81 | |||
| Dataset dimensionality | 100x1000x250 | 100x2000x1000 | 100x2000x3000 | |||
| Chunk dimensionality | 1000x250 | 2000x1000 | 2000x3000 | |||
| Datatype | 4-byte integer | 4-byte integer | 4-byte integer | |||
| IO speed is in MB/s and Time is in second (s). | speed1 | time2 | speed | time | speed | time |
|---|---|---|---|---|---|---|
| H5Dwrite writes without compression filter | 77.27 | 1.23 | 97.02 | 7.86 | 91.77 | 24.94 |
| H5DOwrite_chunk writes uncompressed data | 79 | 1.21 | 95.71 | 7.97 | 89.17 | 25.67 |
| H5Dwrite writes with compression filter | 2.68 | 35.59 | 2.67 | 285.75 | 2.67 | 857.24 |
| H5DOwrite_chunk writes compressed data | 77.19 | 0.83 | 78.56 | 6.53 | 96.28 | 15.98 |
| Unix writes compressed data to Unix file | 76.49 | 0.84 | 95 | 5.4 | 98.59 | 15.61 |
Since H5DOwrite_chunk writes data chunks directly in a file, developers must be careful when using it. The function bypasses hyperslab selection, the conversion of data from one datatype to another, and the filter pipeline to write the chunk. Developers should have experience with these processes before they use this function.
The following is an example of using H5DOwrite_chunk to write an entire dataset by chunk.
Next Chapter HDF5 Standard for Dimension Scales
Navigate back: Main / HDF5 User Guide