|
HDF5 Last Updated on 2026-06-27
The HDF5 Field Guide
|
|
HDF5 Last Updated on 2026-06-27
The HDF5 Field Guide
|
Navigate back: Main / Getting Started with HDF5 / Learning the Basics
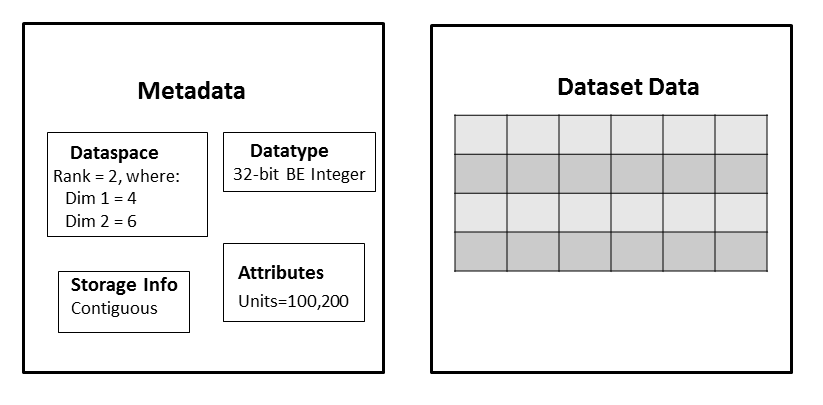
The Creating a Dataset tutorial topic defines a dataset as a multidimensional array of data elements together with supporting metadata, where:
Datatype, dataspace, attribute, and storage layout information were introduced as part of the metadata associated with a dataset:
|
The storage information, or storage layout, defines how the raw data values in the dataset are physically stored on disk. There are three ways that a dataset can be stored:
See the H5Pset_layout/H5Pget_layout APIs for details.
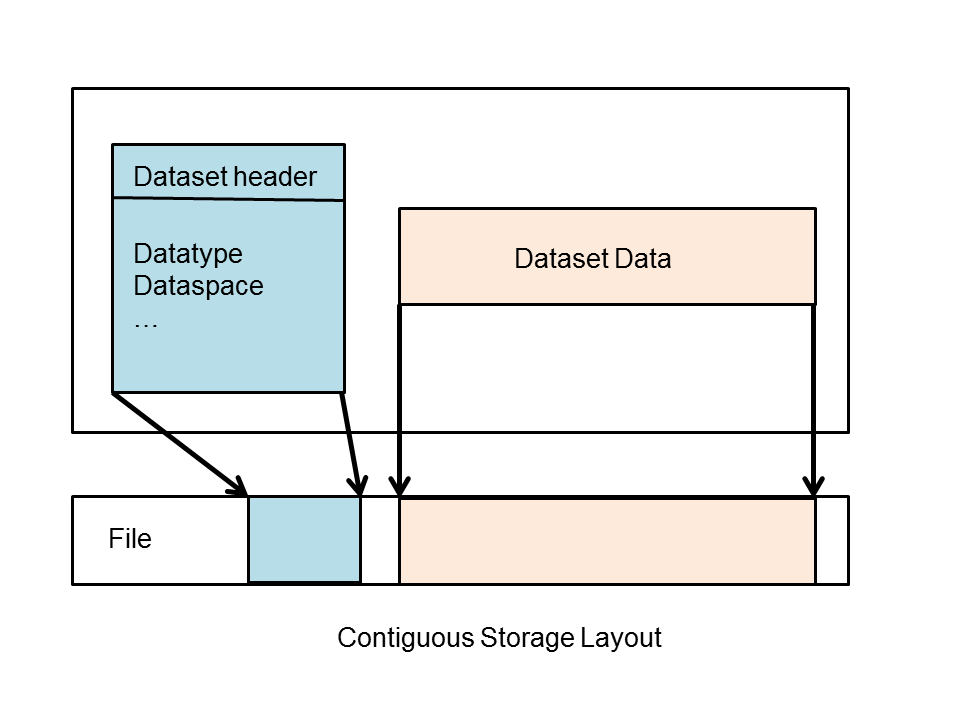
If the storage layout is contiguous, then the raw data values will be stored physically adjacent to each other in the HDF5 file (in one contiguous block). This is the default layout for a dataset. In other words, if you do not explicitly change the storage layout for the dataset, then it will be stored contiguously.
|
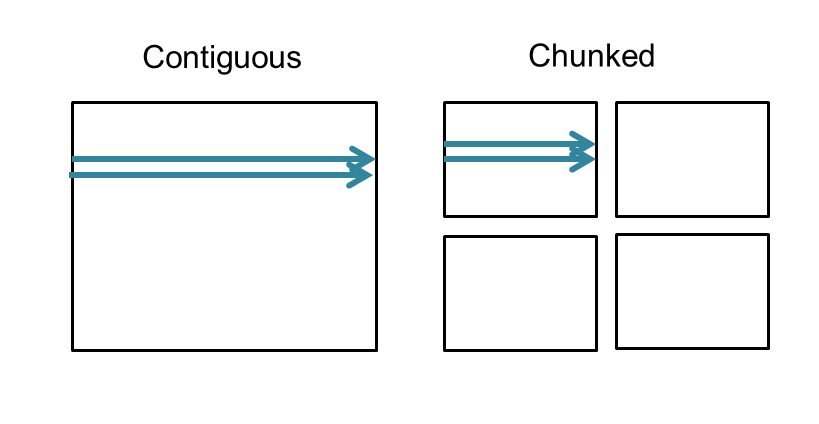
With a chunked storage layout the data is stored in equal-sized blocks or chunks of a pre-defined size. The HDF5 library always writes and reads the entire chunk:
|
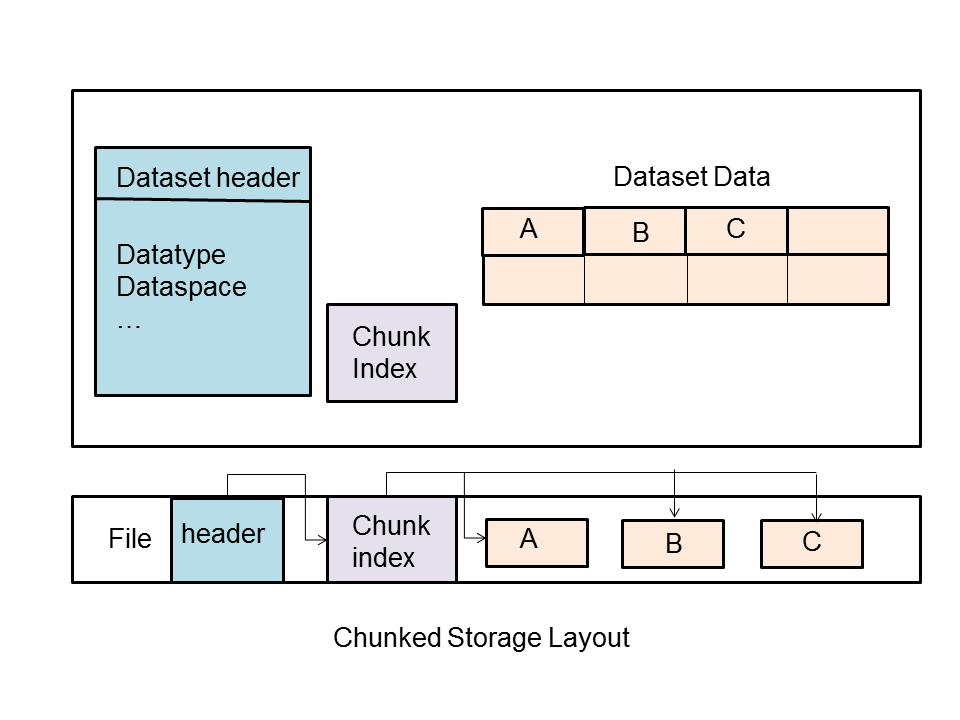
Each chunk is stored as a separate contiguous block in the HDF5 file. There is a chunk index which keeps track of the chunks associated with a dataset:
|
Chunking in HDF5 is required for enabling compression and other filters, as well as for creating extendible or unlimited dimension datasets.
It is also commonly used when subsetting very large datasets. Using the chunking layout can greatly improve performance when subsetting large datasets, because only the chunks required will need to be accessed. However, it is easy to use chunking without considering the consequences of the chunk size, which can lead to strikingly poor performance.
Note that a chunk always has the same rank as the dataset and the chunk's dimensions do not need to be factors of the dataset dimensions.
Writing or reading a chunked dataset is transparent to the application. You would use the same set of operations that you would use for a contiguous dataset. For example:
Issues that can cause performance problems with chunking include:
It is a good idea to:
A compact dataset is one in which the raw data is stored in the object header of the dataset. This layout is for very small datasets that can easily fit in the object header.
The compact layout can improve storage and access performance for files that have many very tiny datasets. With one I/O access both the header and data values can be read. The compact layout reduces the size of a file, as the data is stored with the header which will always be allocated for a dataset. However, the object header is 64 KB in size, so this layout can only be used for very small datasets.
To modify the storage layout, the following steps must be done:
The C example to create a chunked dataset is: h5ex_d_chunk.c The C example to create a compact dataset is: h5ex_d_compact.c
The dataset layout is a Dataset Creation Property List. This means that once the dataset has been created the dataset layout cannot be changed. The h5repack utility can be used to write a file to a new with a new layout.
Previous Chapter Property Lists Basics - Next Chapter Extendible Datasets
Navigate back: Main / Getting Started with HDF5 / Learning the Basics